
- 公開日:
PDFで文字を全文検索できるようにするフリーソフト3選
PDFファイルは書類の保存や共有に便利なフォーマットですが、いざ必要な情報を探そうとすると、膨大なページ数から目的の箇所を見つけるのは大変ですよね。そんな時に役立つのが、PDFの全文検索機能です。
全文検索は、ドキュメント内の特定の文字列や単語を見つけ出すための機能です。しかし、中には全文検索ができないPDFファイルもあります。
PDFで文字を全文検索できるようにするフリーソフトを3つご紹介します。
LightPDFの基本情報
LightPDF
日本語: 〇
オンライン(インストール不要): 〇
オフライン(インストール型): 〇
LightPDFでPDFの文字を全文検索できるようにする方法
LightPDFは、変換や編集などさまざまな機能が利用できるPDF変換ツールです。オンライン版やデスクトップ版、アプリ版などがあります。
OCR機能により、PDFの文字が全文検索できるようになります。アカウント登録などの面倒な手続きなく、OCR処理が可能です。
今回はWindows 11を使って、デスクトップ版のLightPDFでPDFの文字を全文検索できるようにする方法をご紹介します。
LightPDFを起動します。
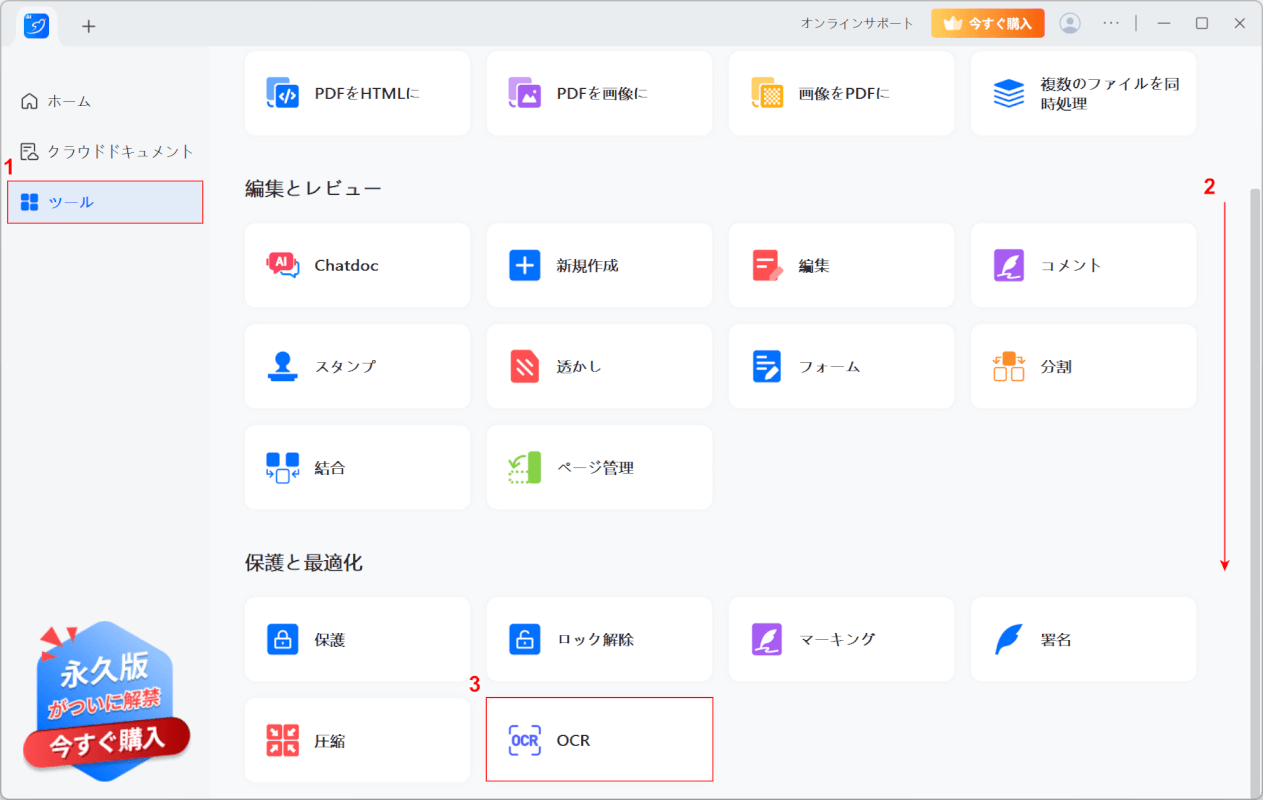
①「ツール」タブを選択し、②画面を下にスクロールし、③「OCR」を選択します。
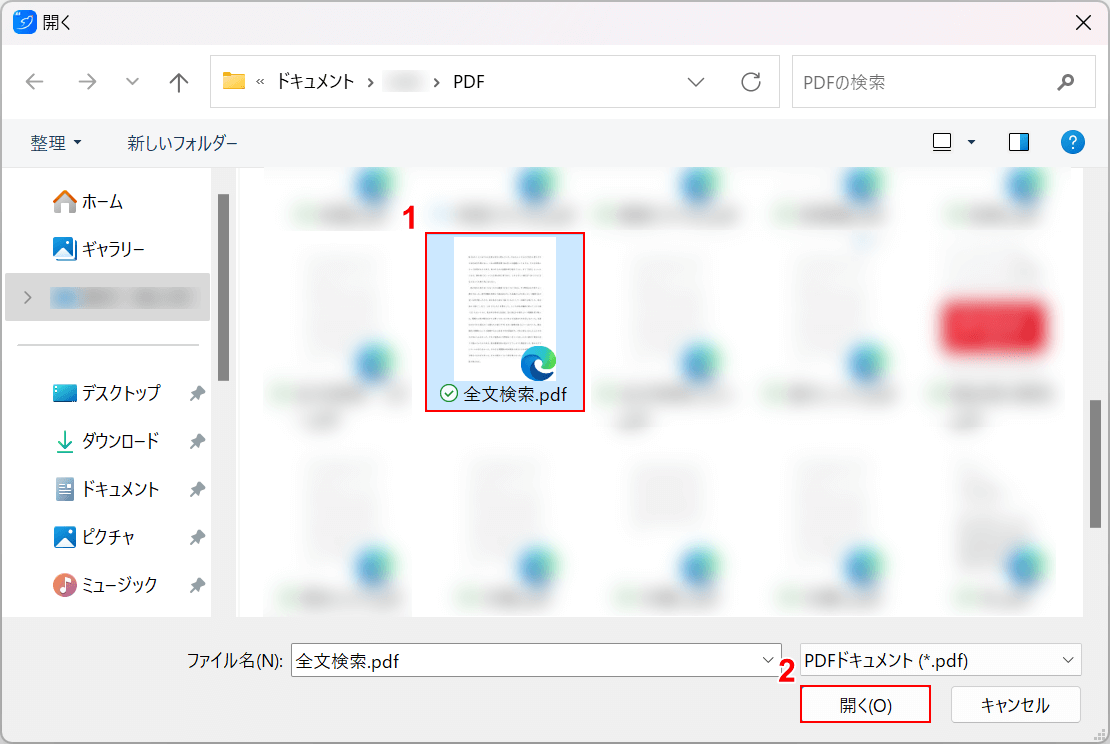
「開く」ダイアログボックスが表示されます。
①任意のファイル(例:全文検索.pdf)を選択し、②「開く」ボタンを押します。
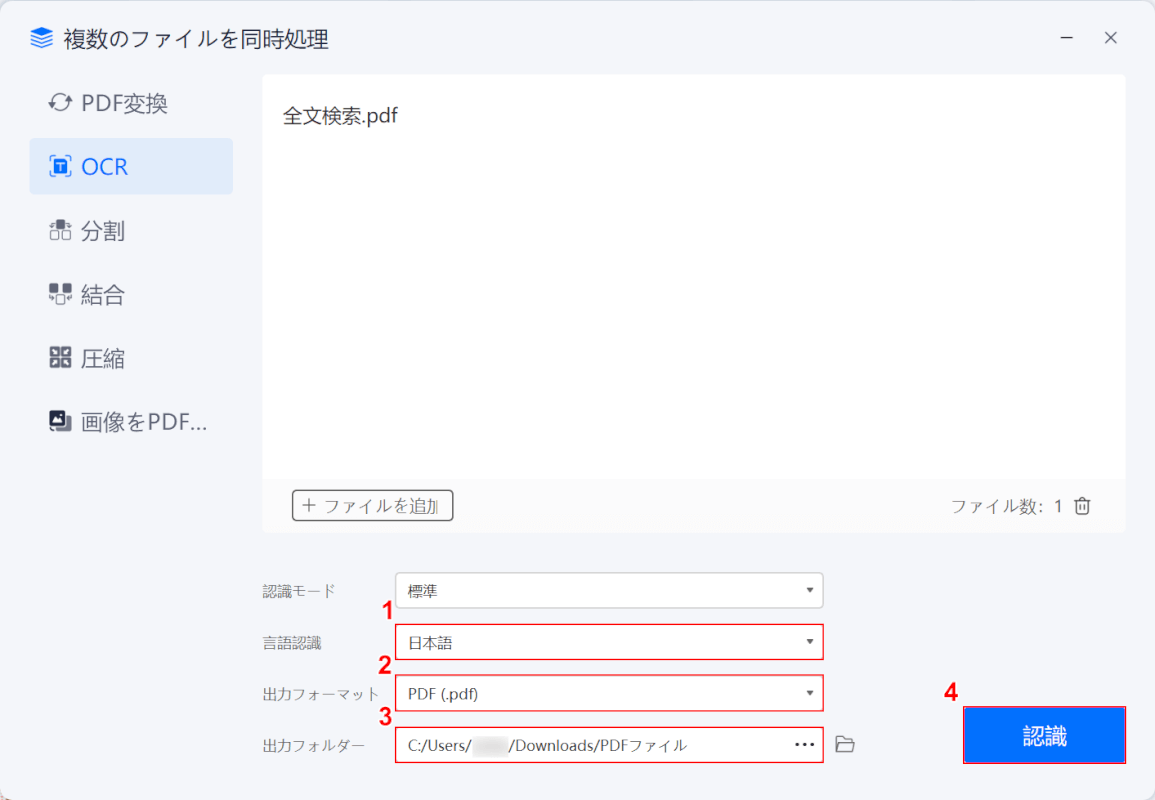
①言語認識で任意の言語(例:日本語)、②出力フォーマットで「PDF(.pdf)」の順に選択し、③任意の出力先を入力します。
④「認識」ボタンを押します。
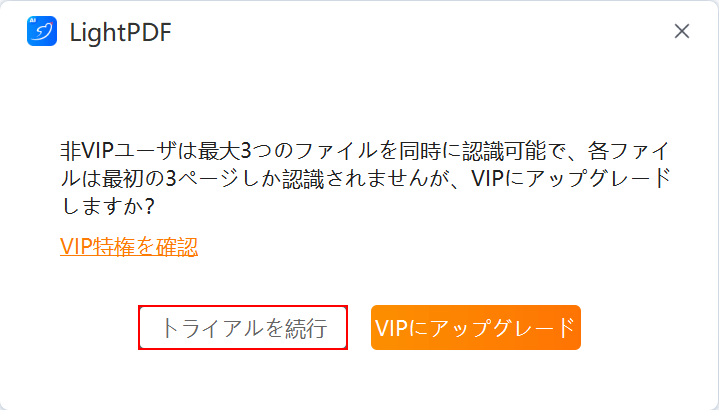
「LightPDF」ダイアログボックスが表示されます。
「トライアルを続行」ボタンを押します。
変換と保存が完了したので、文字を全文検索できるか確認していきます。
保存先のフォルダにファイルが保存されているので、ダブルクリックで開きます。
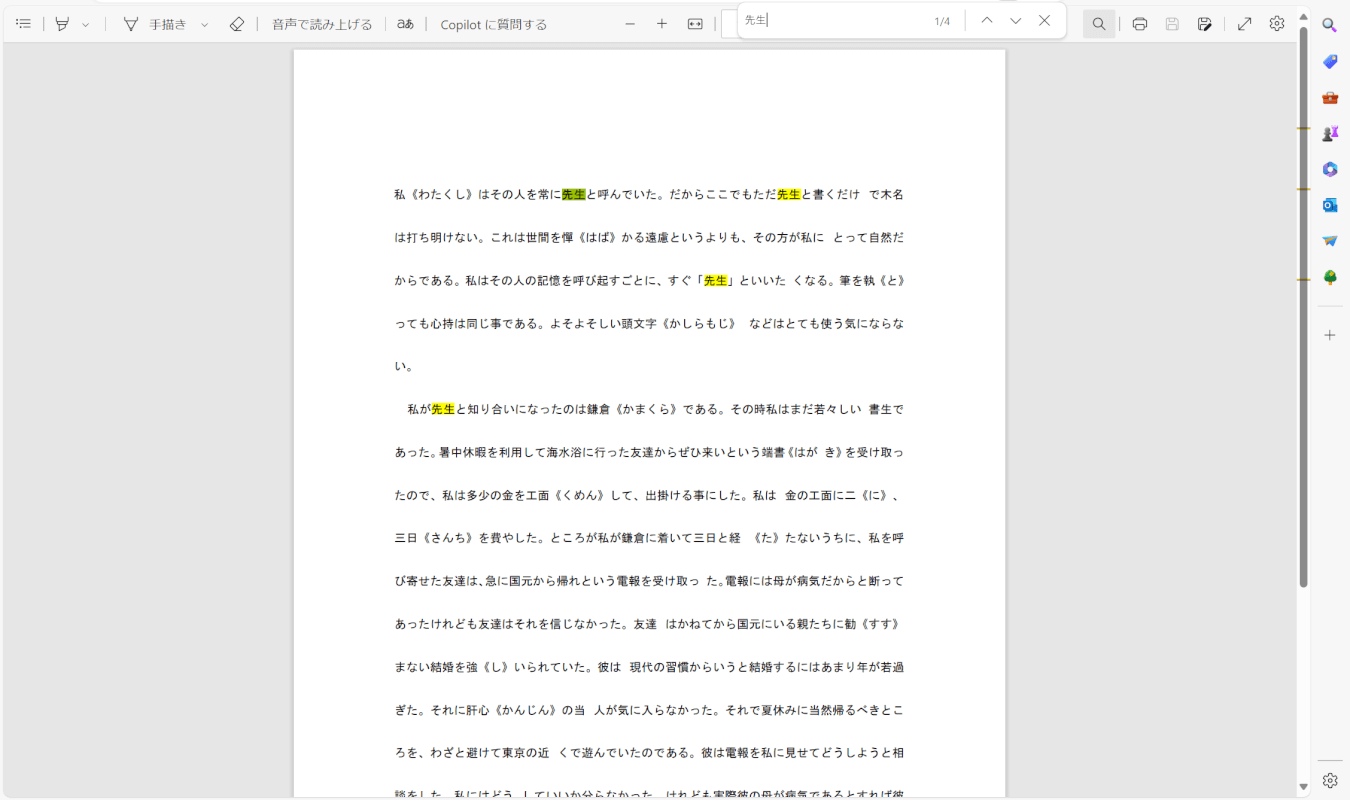
テキスト検索をしてテキストが認識されていれば、正しくPDFの文字を全文検索できています。
Sejdaの基本情報
Sejda
日本語: 〇
オンライン(インストール不要): 〇
オフライン(インストール型): 〇
SejdaでPDFの文字を全文検索できるようにする方法
Sejdaは、オランダの「Sejda」が運営しているPDFエディタです。オンライン版やデスクトップ版などがあり、様々なOSやデバイスから利用可能です。
PDF内のテキストを検索可能にする直接の機能はありませんが、「OCR」機能を使って検索可能にすることができます。
今回はWindows 11を使って、デスクトップ版のSejdaでPDFの文字を全文検索できるようにする方法をご紹介します。
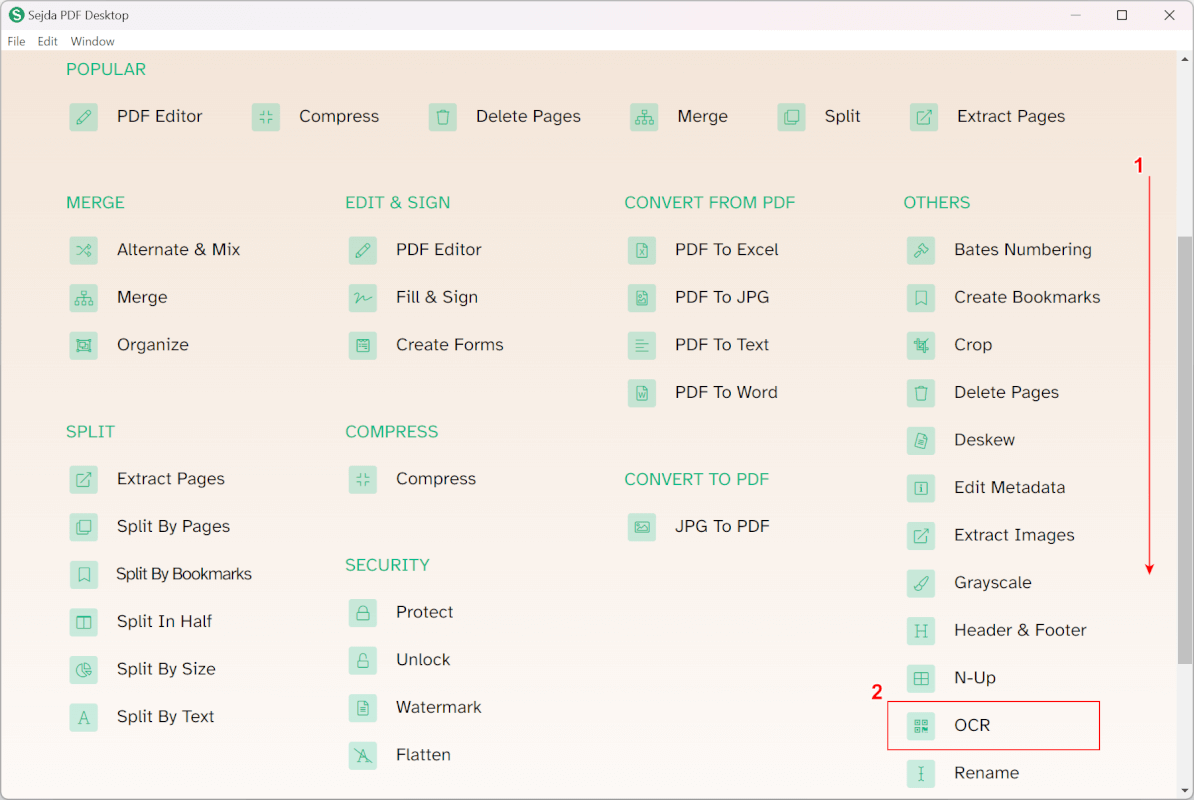
Sejdaを起動します。
①画面を下にスクロールし、②「OCR」を選択します。
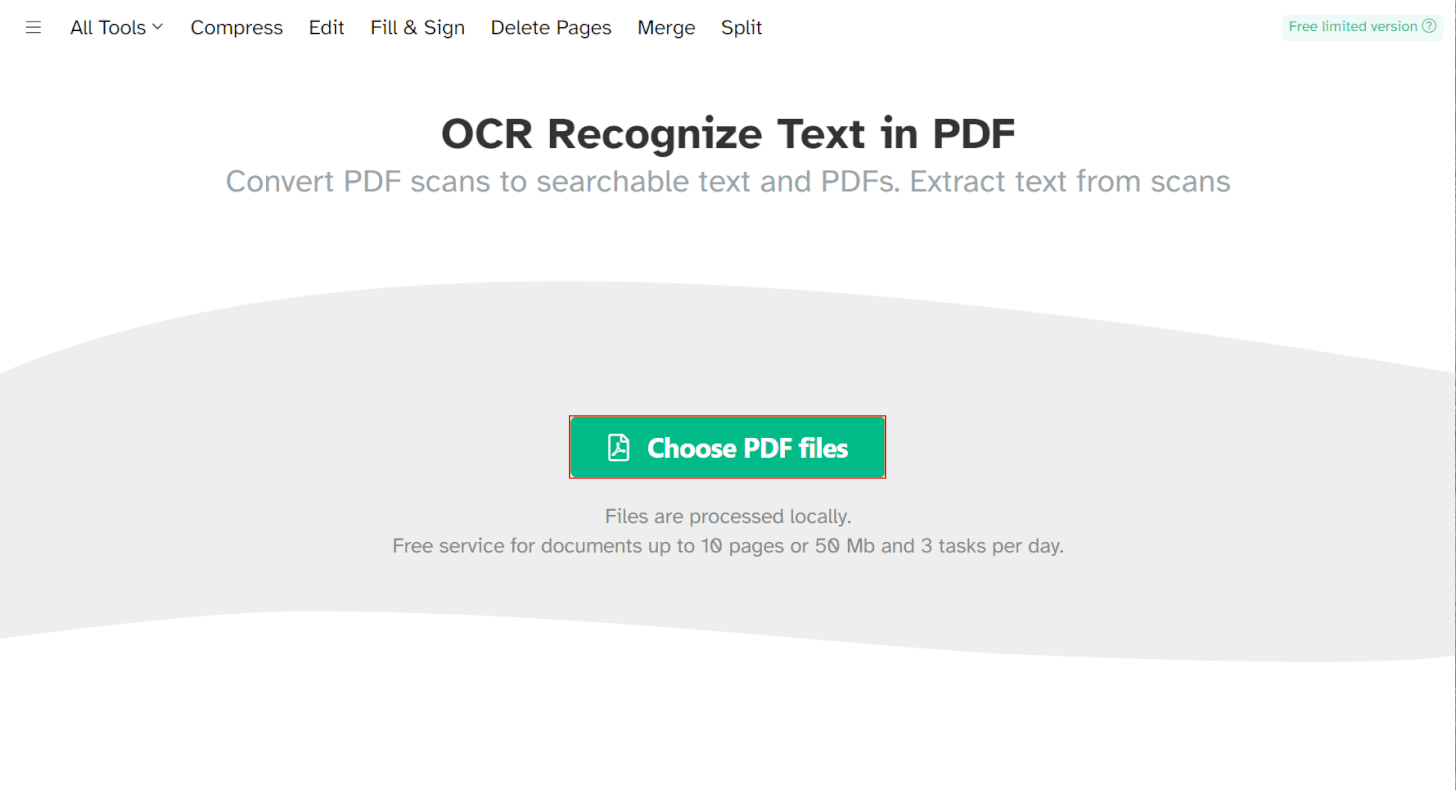
OCRツールが開きます。
画面中央の「Choose PDF files」ボタンを押します。
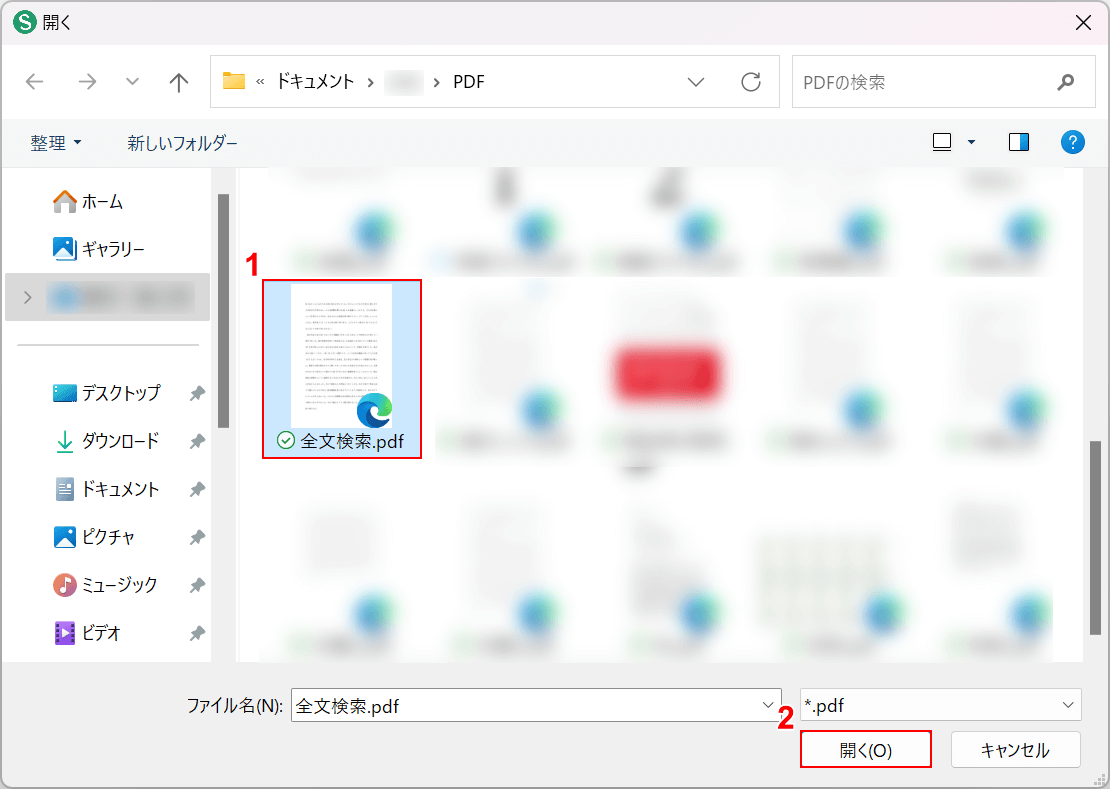
「開く」ダイアログボックスが表示されます。
①任意のファイル(例:全文検索.pdf)を選択し、②「開く」ボタンを押します。
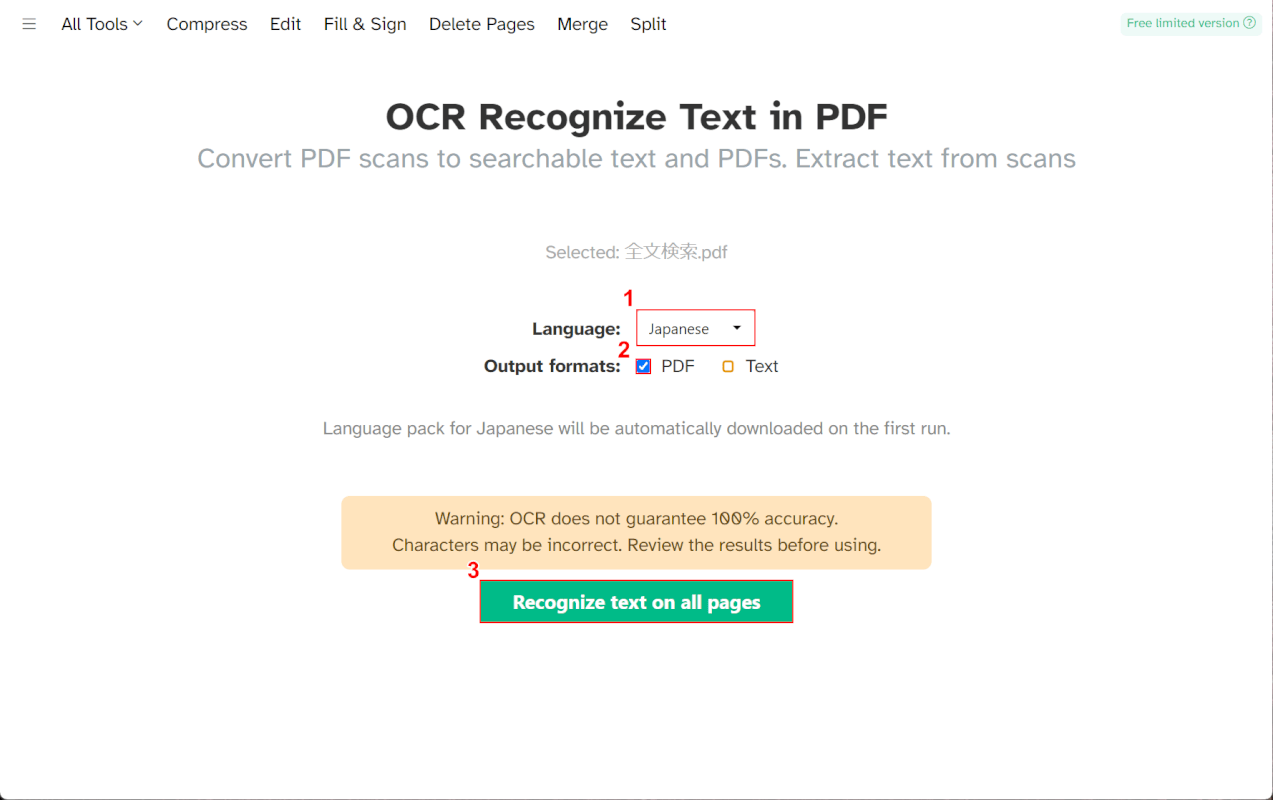
①Languageで任意の言語(例:Japanese)を選択し、②Output formatsで「PDF」に✓を入れます。
③「Recognize text on all pages」ボタンを押します。
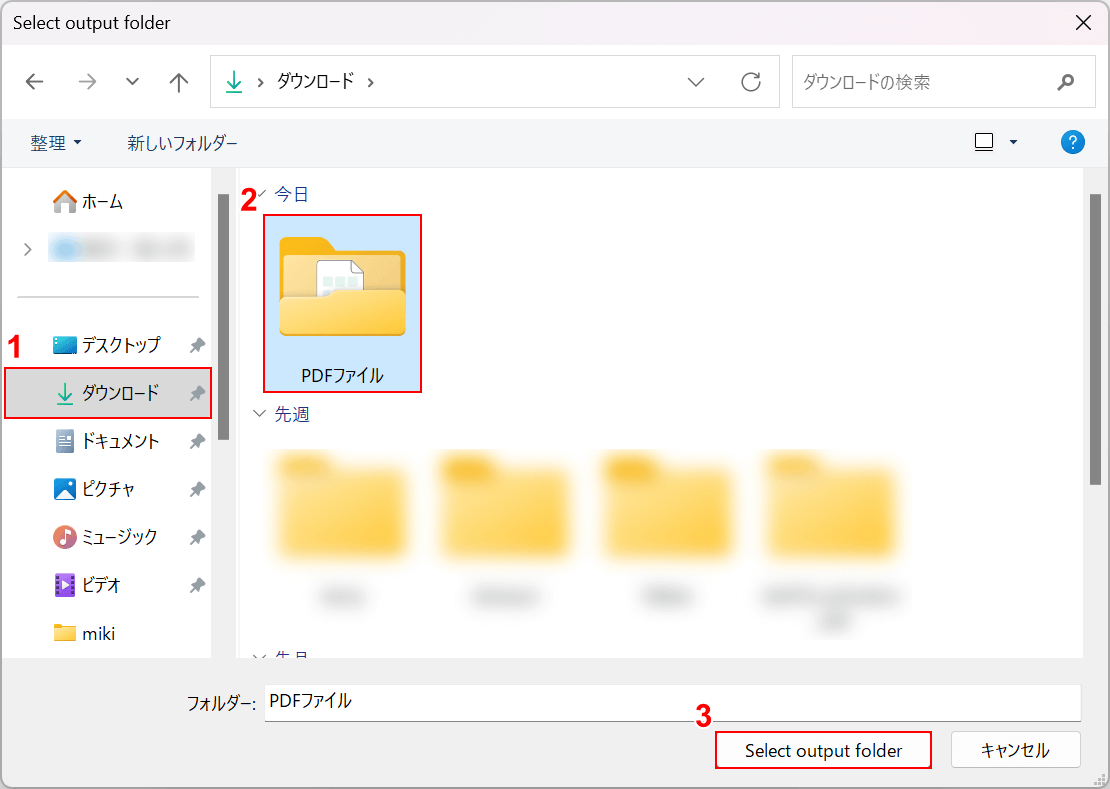
「Select output folder」ダイアログボックスが表示されます。
①任意の保存先(例:ダウンロード)、②保存先のフォルダ(例:PDFファイル)の順に選択し、③「Select output folder」ボタンを押します。
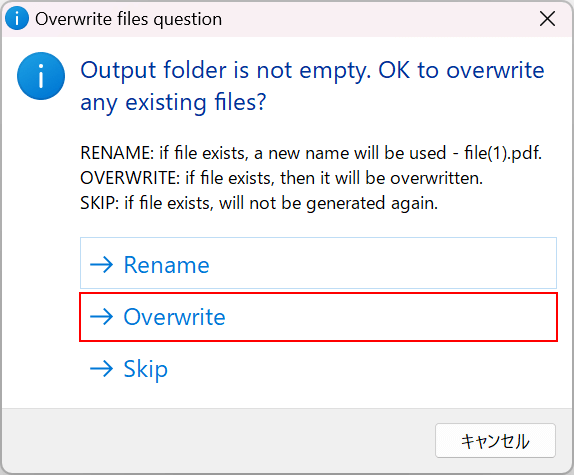
「Overwrite files question」ダイアログボックスが表示されます。
任意の保存形式(例:Overwrite)を選択します。
変換と保存が完了したので、文字を全文検索できるか確認していきます。
保存先のフォルダにファイルが保存されているので、ダブルクリックで開きます。
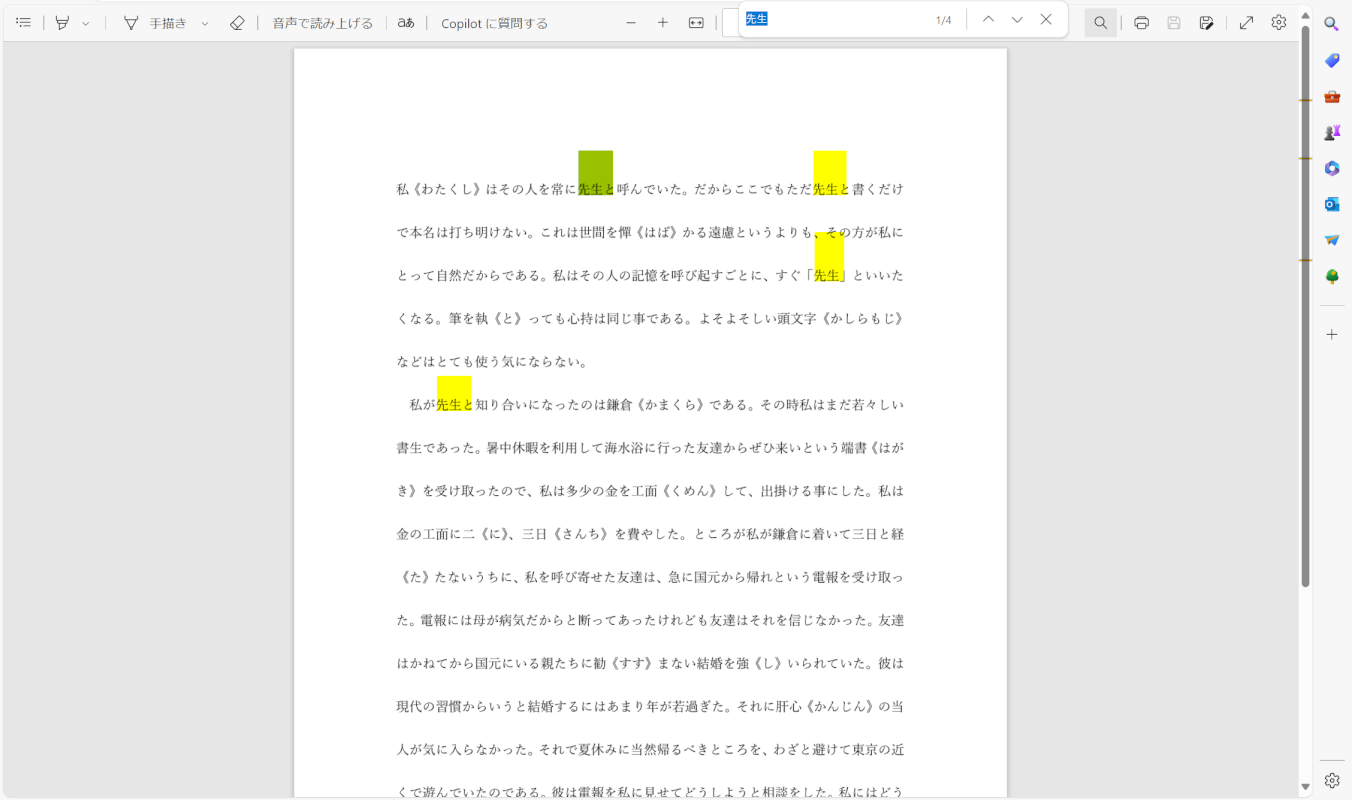
テキスト検索をしてテキストが認識されていれば、正しくPDFの文字を全文検索できています。
Foxit PDF Editorの基本情報
Foxit PDF Editor
日本語: 〇
オンライン(インストール不要): ×
オフライン(インストール型): 〇
Foxit PDF EditorでPDFの文字を全文検索できるようにする方法
Foxit PDF Editorは、PDFの表示や作成、編集ができるPDFマルチツールです。株式会社FoxitJapanが運営しています。
簡単なアカウント登録をすれば無料版のダウンロードが可能です。無料版は有料版のほとんどの機能を使用できますが、試用期限はダウンロードから14日間です。
今回はWindows 11を使って、デスクトップ版のFoxit PDF EditorでPDFの文字を全文検索できるようにする方法をご紹介します。
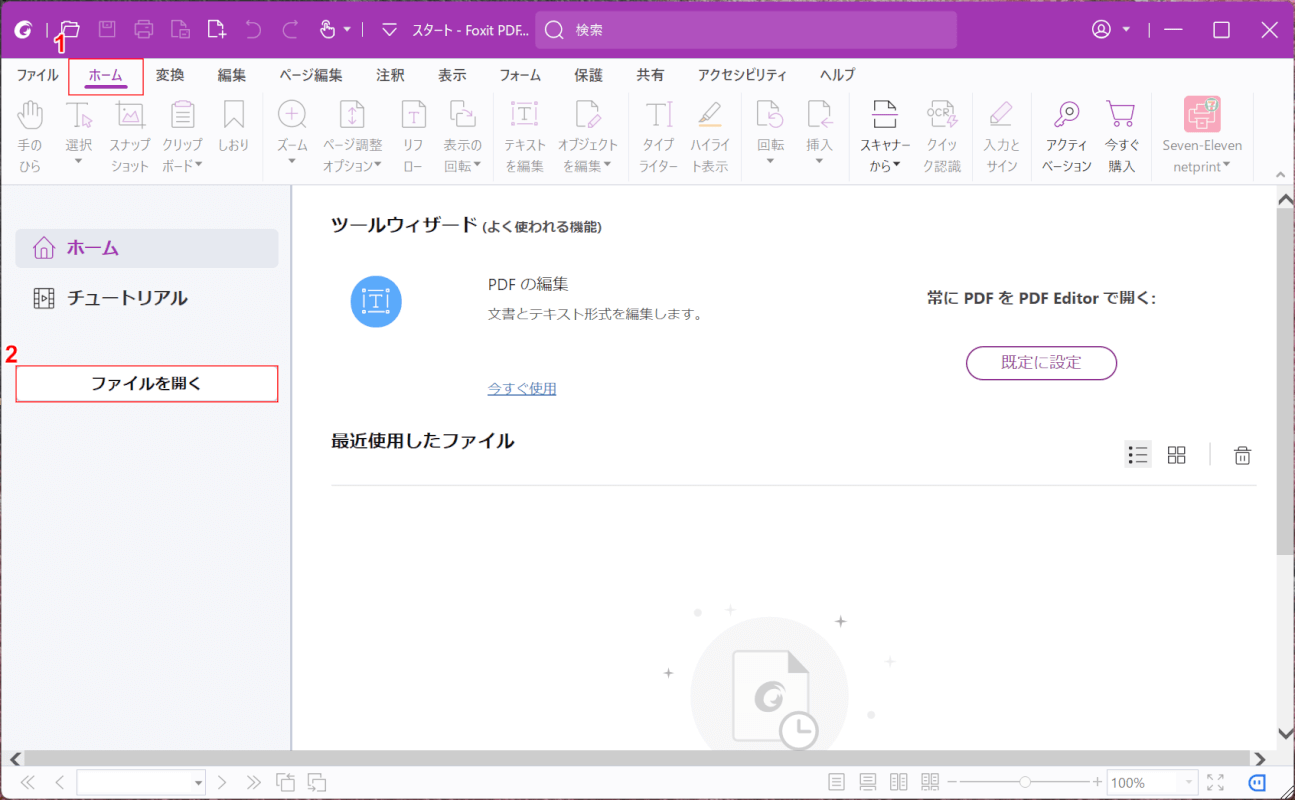
Foxit PDF Editorを起動します。
①「ホーム」タブを選択し、②「ファイルを開く」ボタンを押します。
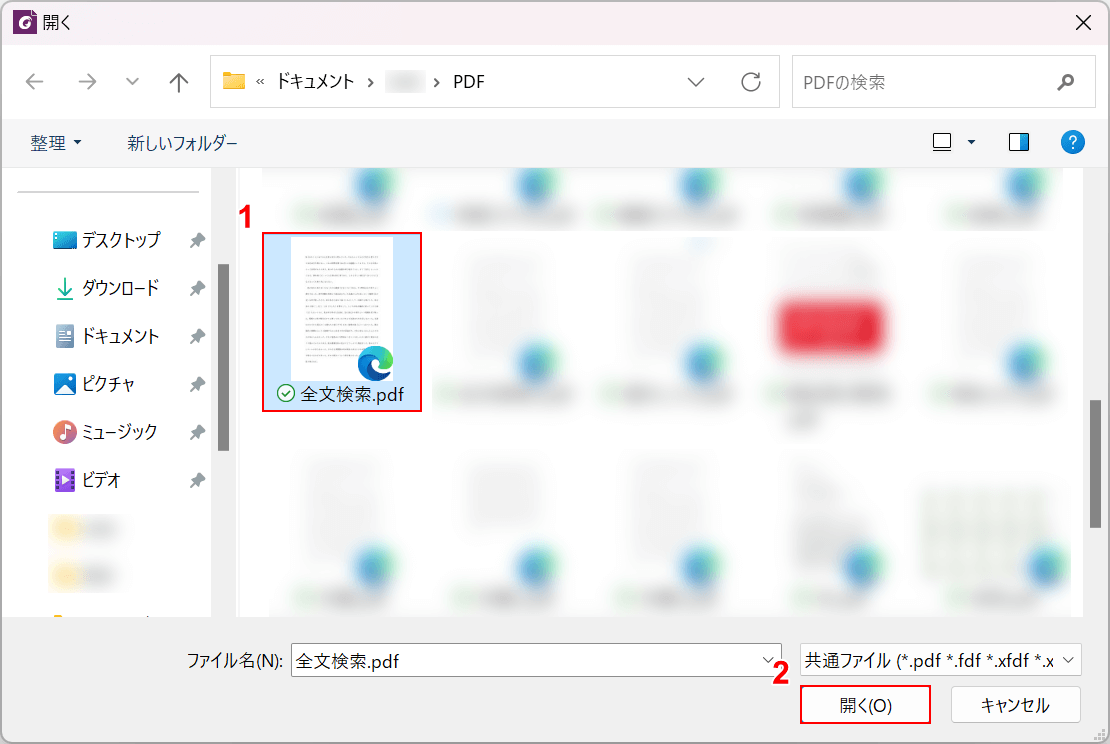
「開く」ダイアログボックスが表示されます。
①任意のファイル(例:全文検索.pdf)を選択し、②「開く」ボタンを押します。
選択したファイルがFoxit PDF Editorに読み込まれます。
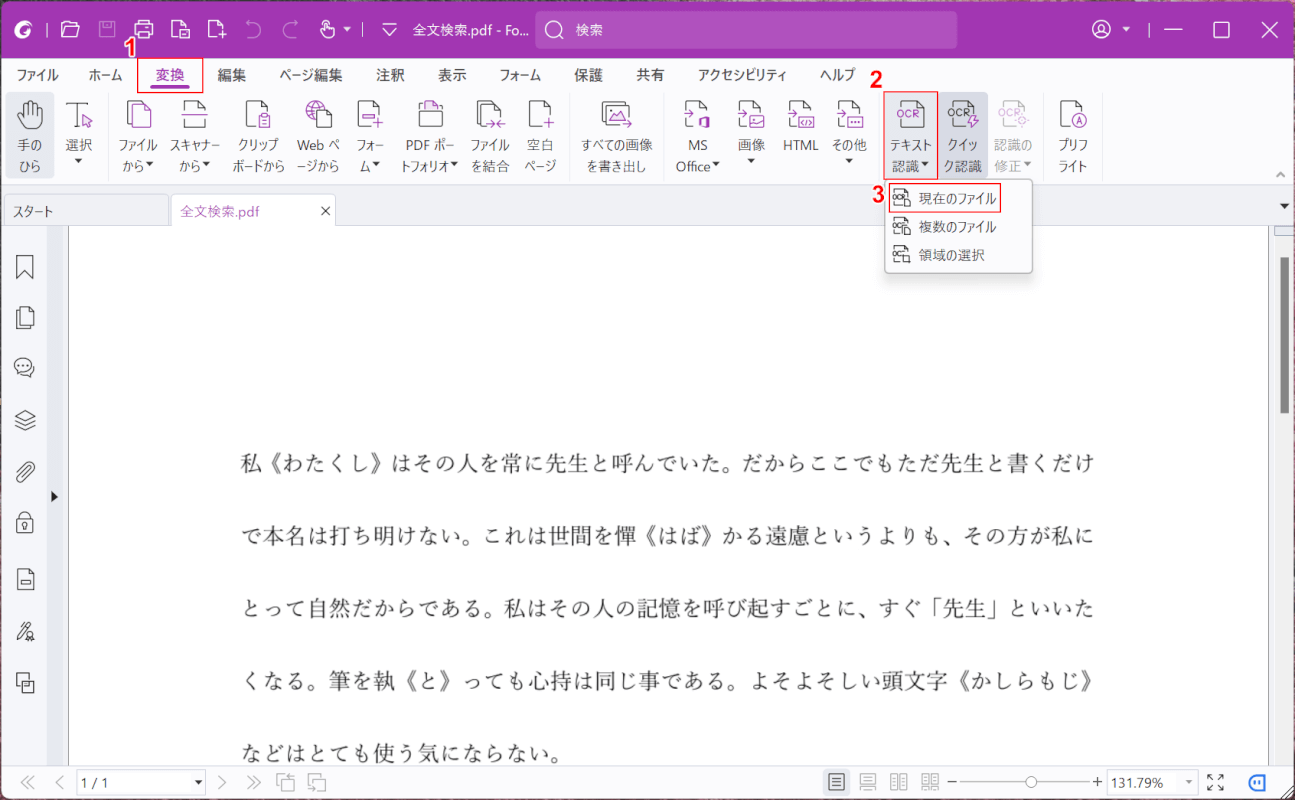
①「変換」タブ、②「テキスト認識」、③「現在のファイル」の順に選択します。
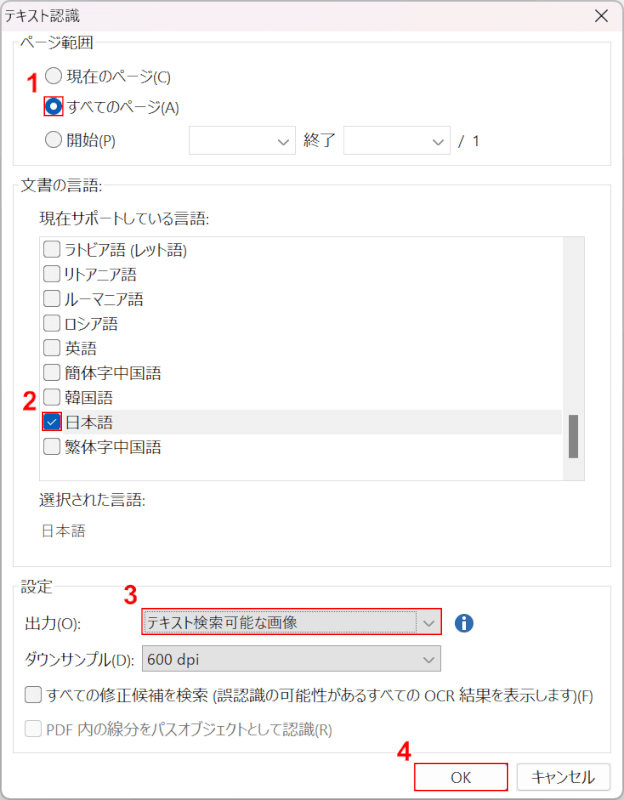
「テキスト認識」ダイアログボックスが表示されます。
①ページ範囲(例:すべてのページ)、②任意の言語(例:日本語)、③任意の出力結果(例:テキスト検索可能な画像)の順に選択します。
④「OK」ボタンを押すと変換が始まります。
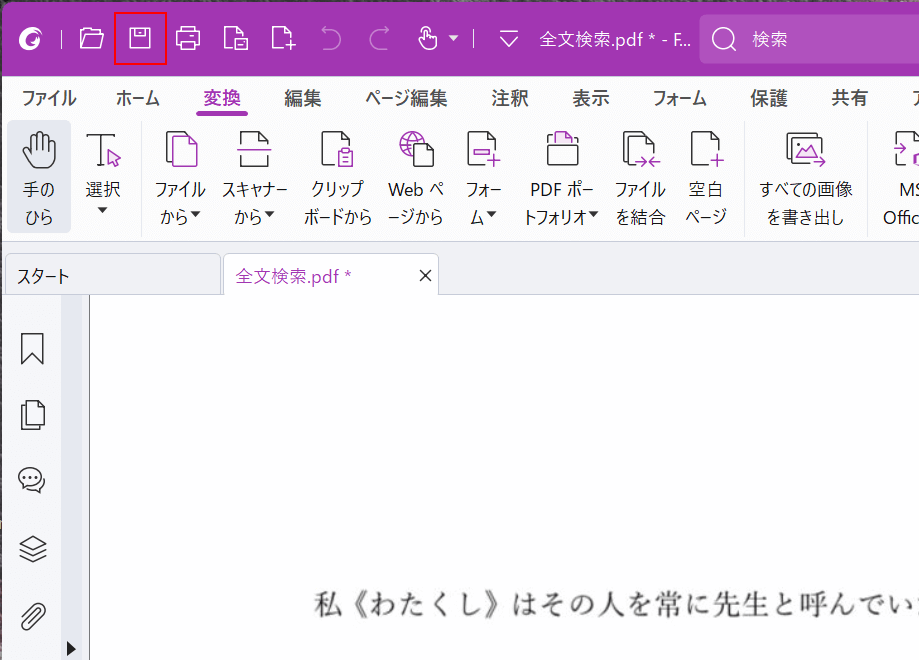
変換ができたら、ファイルを保存します。
画面左上の「上書き保存」を選択します。
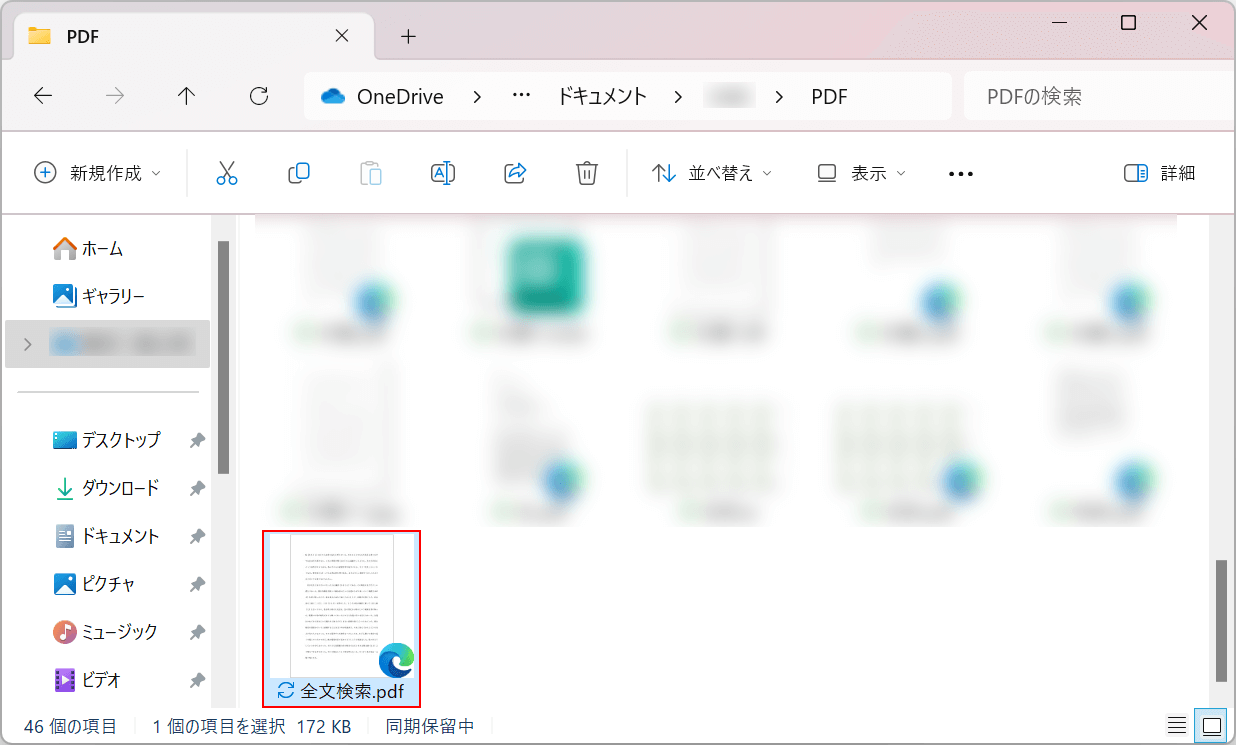
上書き保存されました。
文字を全文検索できるか確認するために、ファイルを選択して開きます。

テキスト検索をしてテキストが認識されていれば、正しくPDFの文字を全文検索できています。
問題は解決できましたか?
記事を読んでも問題が解決できなかった場合は、無料でAIに質問することができます。回答の精度は高めなので試してみましょう。
- 質問例1
- PDFを結合する方法を教えて
- 質問例2
- iLovePDFでできることを教えて
コメント
この記事へのコメントをお寄せ下さい。