
- 公開日:
Macで利用できるPDFのOCRフリーソフト3選
OCRによりPDFファイルに記載された内容をテキストデータとして抽出することで、複製や編集、検索が容易になります。
また、PDFファイルのテキストを手入力しなおす必要がなくなり、大量のデータを効率的にテキスト化することが可能です。
いずれも無料でOCR処理ができるソフトをご紹介しています。
AvePDFの基本情報
AvePDF
- 会員登録なしでPDFのメタデータを消すために使用。 改定する際、制限が少しきついが、このようなオンラインサービスは他にはないので高評価。 制限も、一回きりであればお得
日本語: 〇
オンライン(インストール不要): 〇
オフライン(インストール型): ×
AvePDFを使ってMacでPDFのOCR機能を利用する方法
AvePDFを使ってMacでPDFのOCR機能を利用する方法をご紹介します。
オンライン版のみのリリースのため、WindowsやMacなどさまざまなOSやブラウザに対応しており、無料版と有料版があります。
無料版はアカウント登録などが不要で、有料版のすべての機能をすぐ使用できます。
今回はmacOS 14.1.1を使って、AvePDFのオンライン版でPDFのOCR機能を利用する方法をご紹介します。
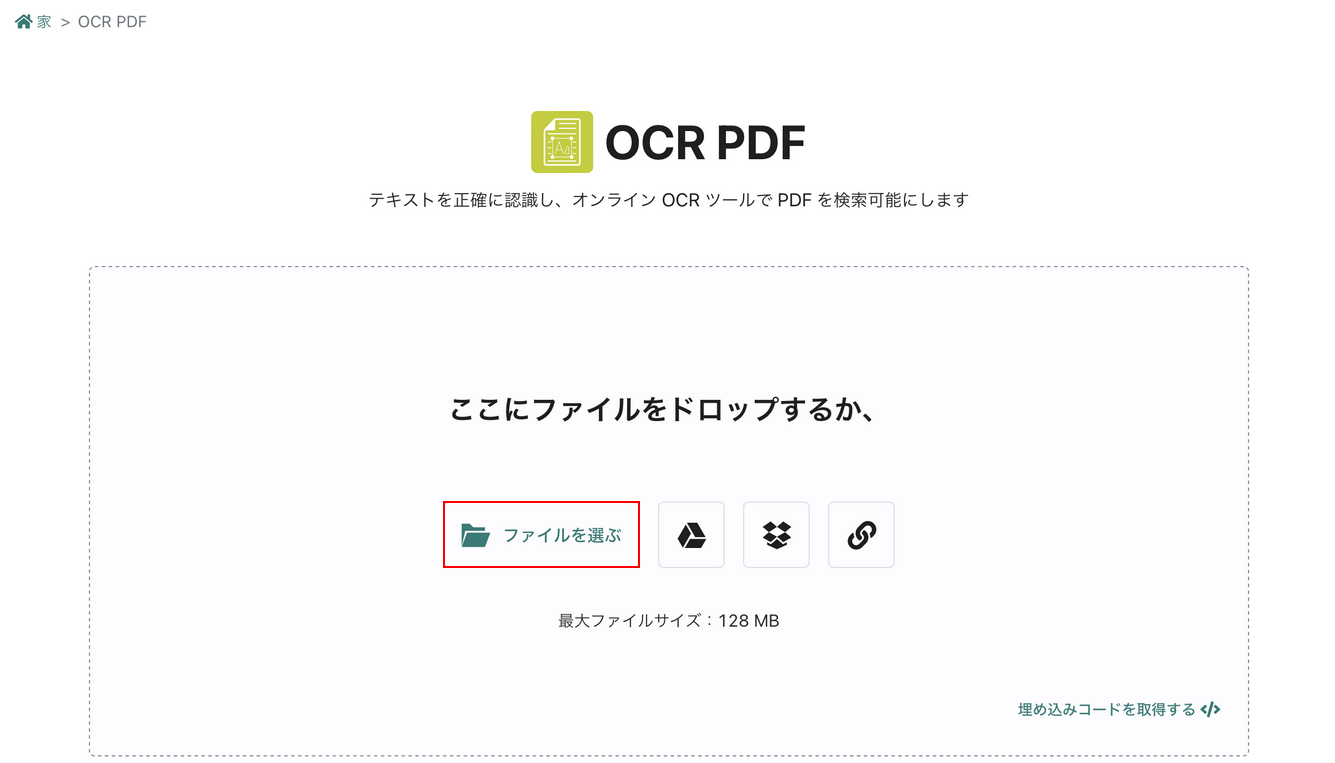
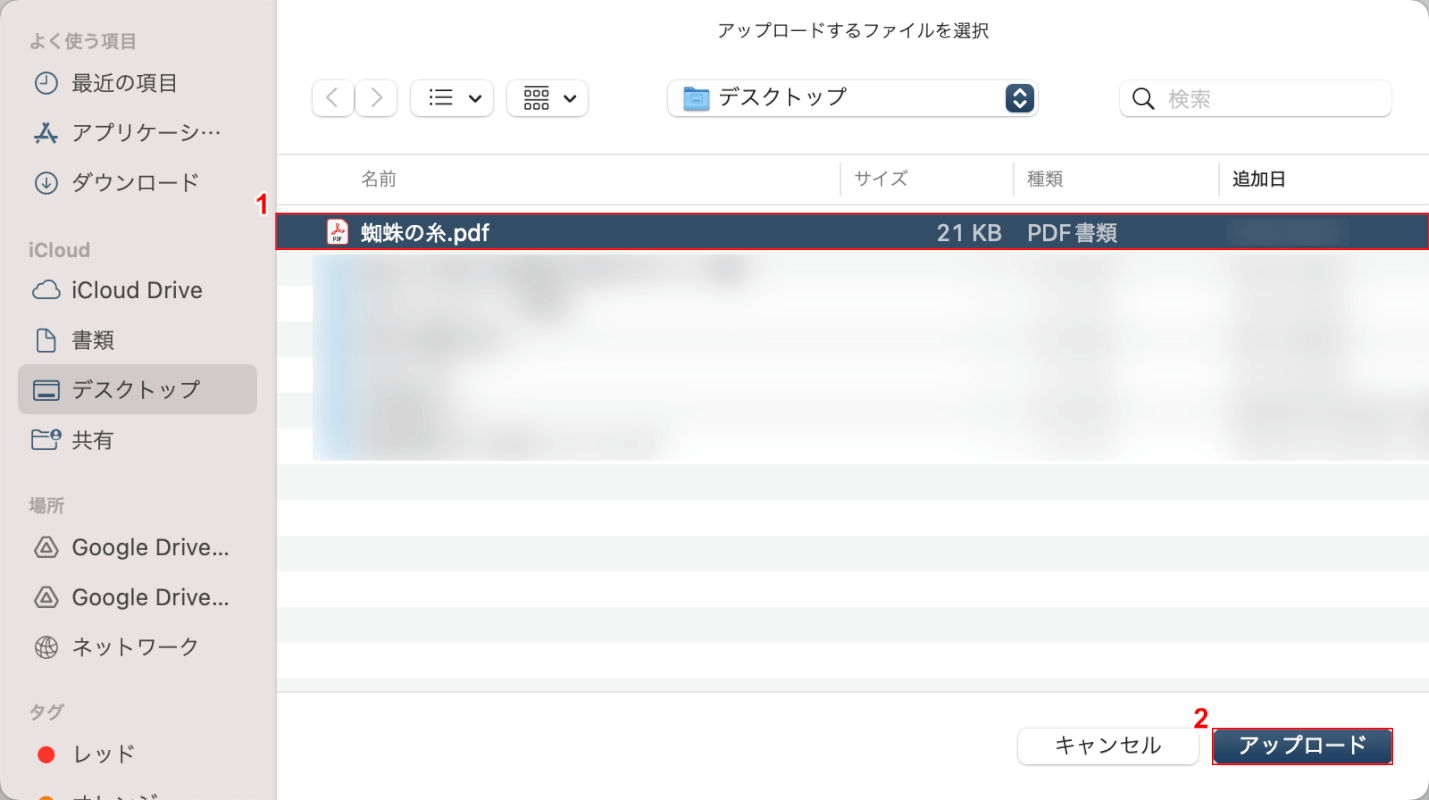
①OCR処理したいPDFファイル(例:蜘蛛の糸)を選択し、②「アップロード」ボタンを押します。
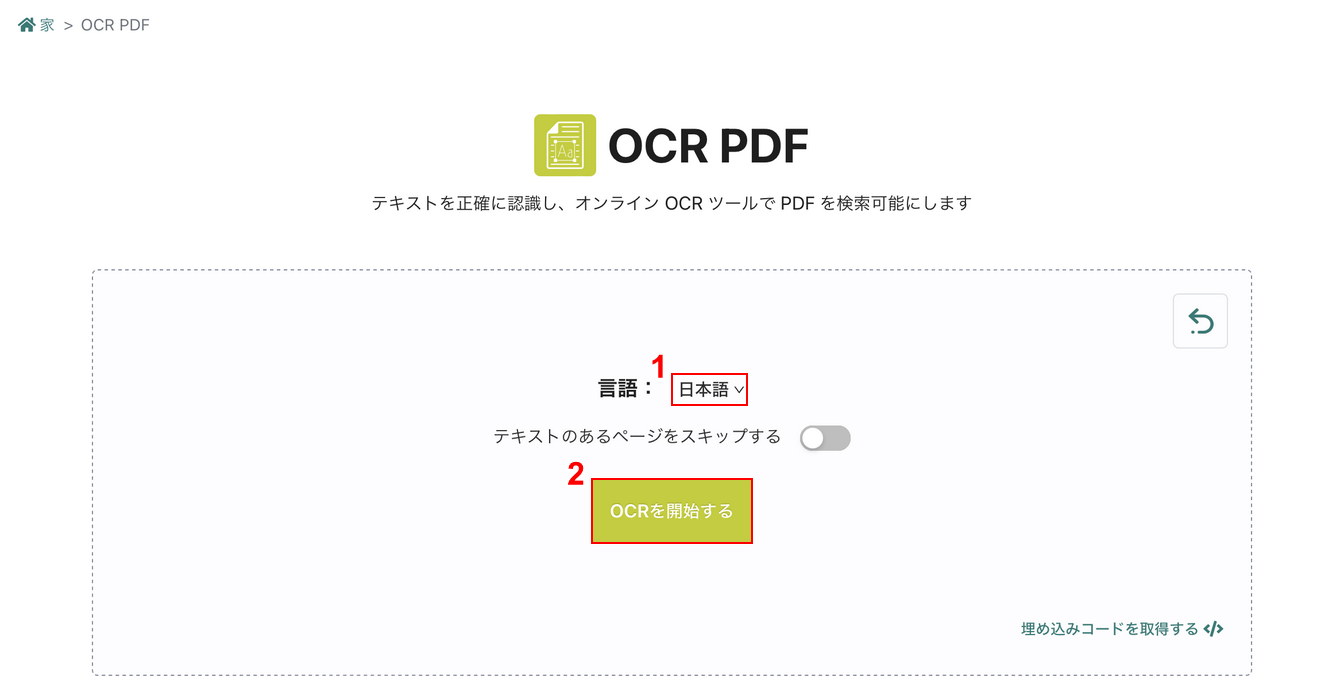
①「言語」でPDFに含まれるテキスト言語(例:日本語)を選択し、②「OCRを開始する」ボタンを押します。
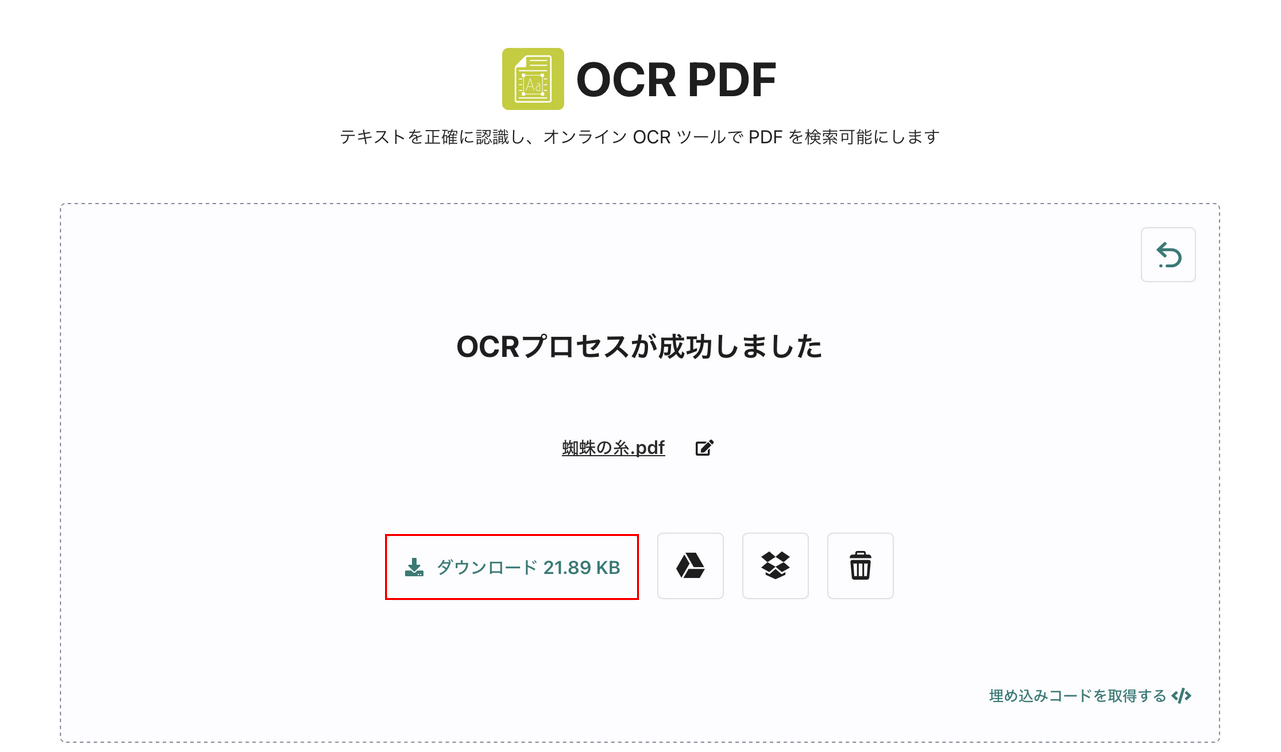
変換が完了すると、「OCRプロセスが成功しました」と表示されます。
「ダウンロード」ボタンを押します。
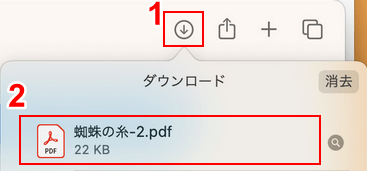
①ブラウザの「ダウンロード」ボタンを押し、②変換したファイル(例:蜘蛛の糸-2)を選択して開きます。
なお、上の画像はSafariで開いたものです。
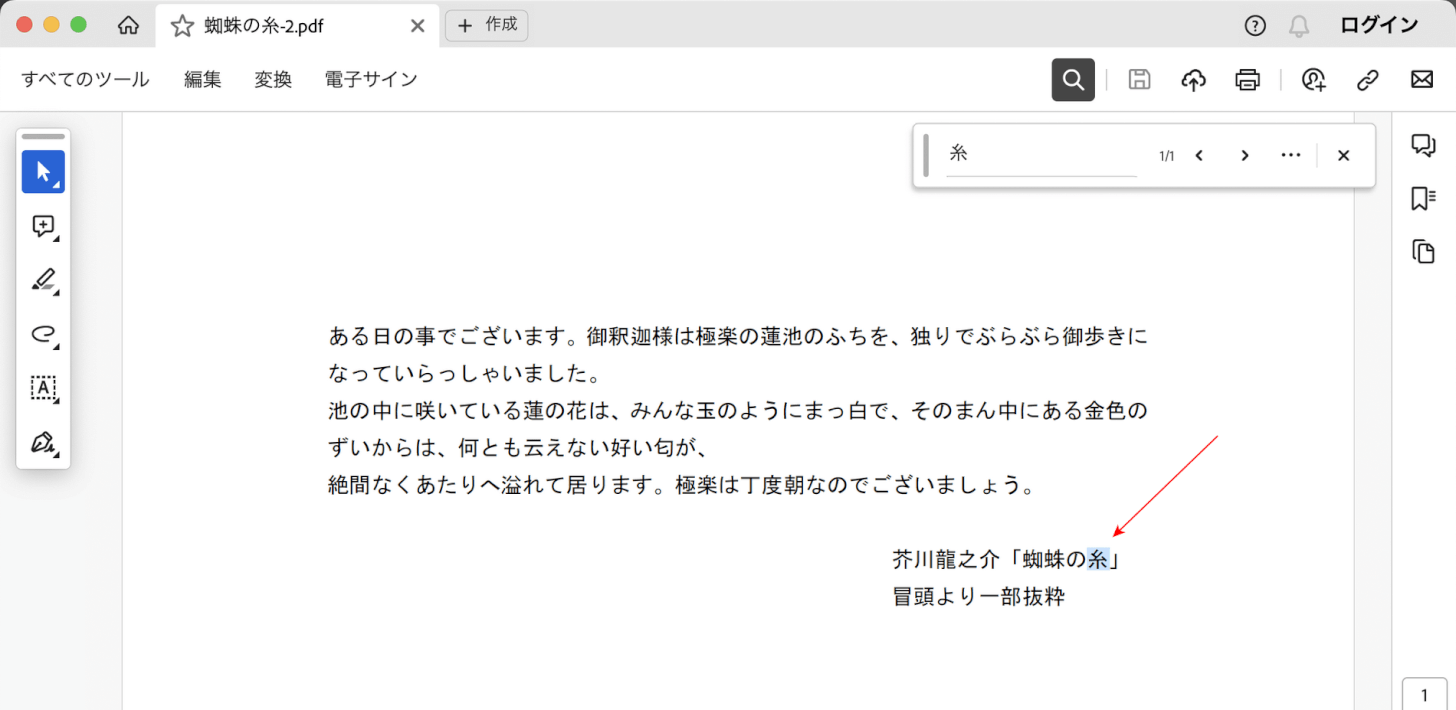
上の画像はAdobe Acrobat ReaderでPDFを開いたものです。
赤矢印で示す通りテキストを認識しており、OCR処理をすることができました。
Xodo PDF Reader & Editorの基本情報
Xodo PDF Reader & Editor
日本語: 〇
オンライン(インストール不要): 〇
オフライン(インストール型): 〇
Xodo PDF Reader & Editorを使ってMacでPDFのOCR機能を利用する方法
Xodo PDF Reader & Editorを使ってMacでPDFのOCR機能を利用する方法をご紹介します。
基本的に無料版は有料版の「お試し」のような位置づけとなり、1日1回までであれば有料版の機能をすべて利用できます。
今回はmacOS 14.1.1を使って、Xodo PDF Reader & Editorのオンライン版でPDFのOCR機能を利用する方法をご紹介します。
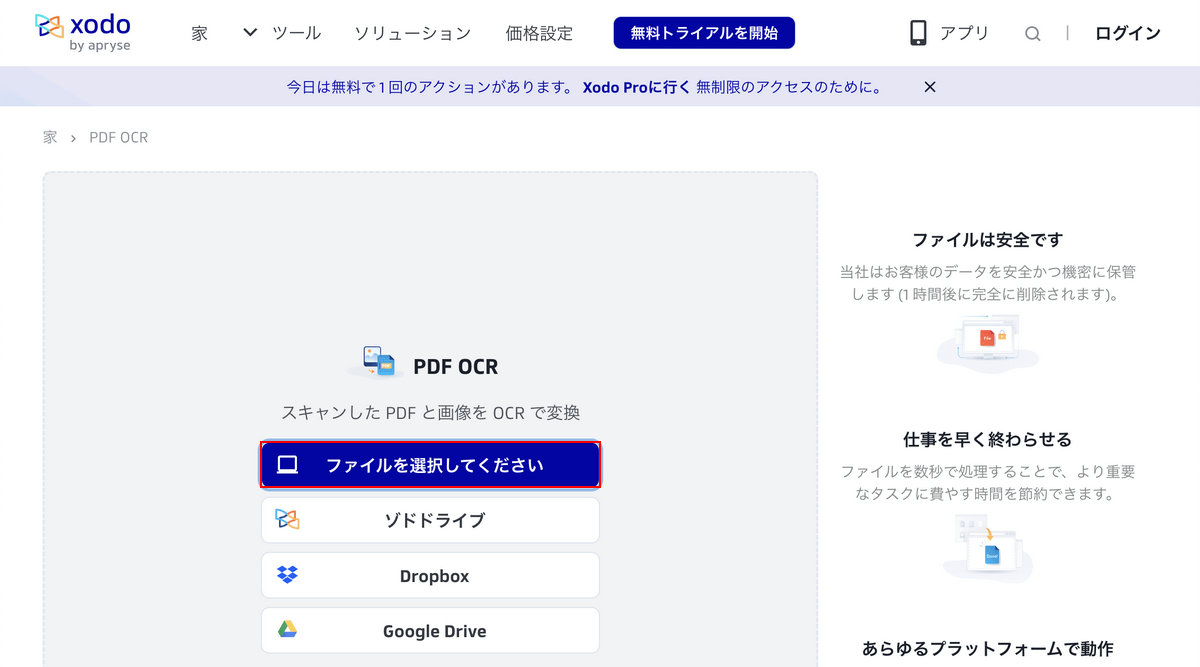
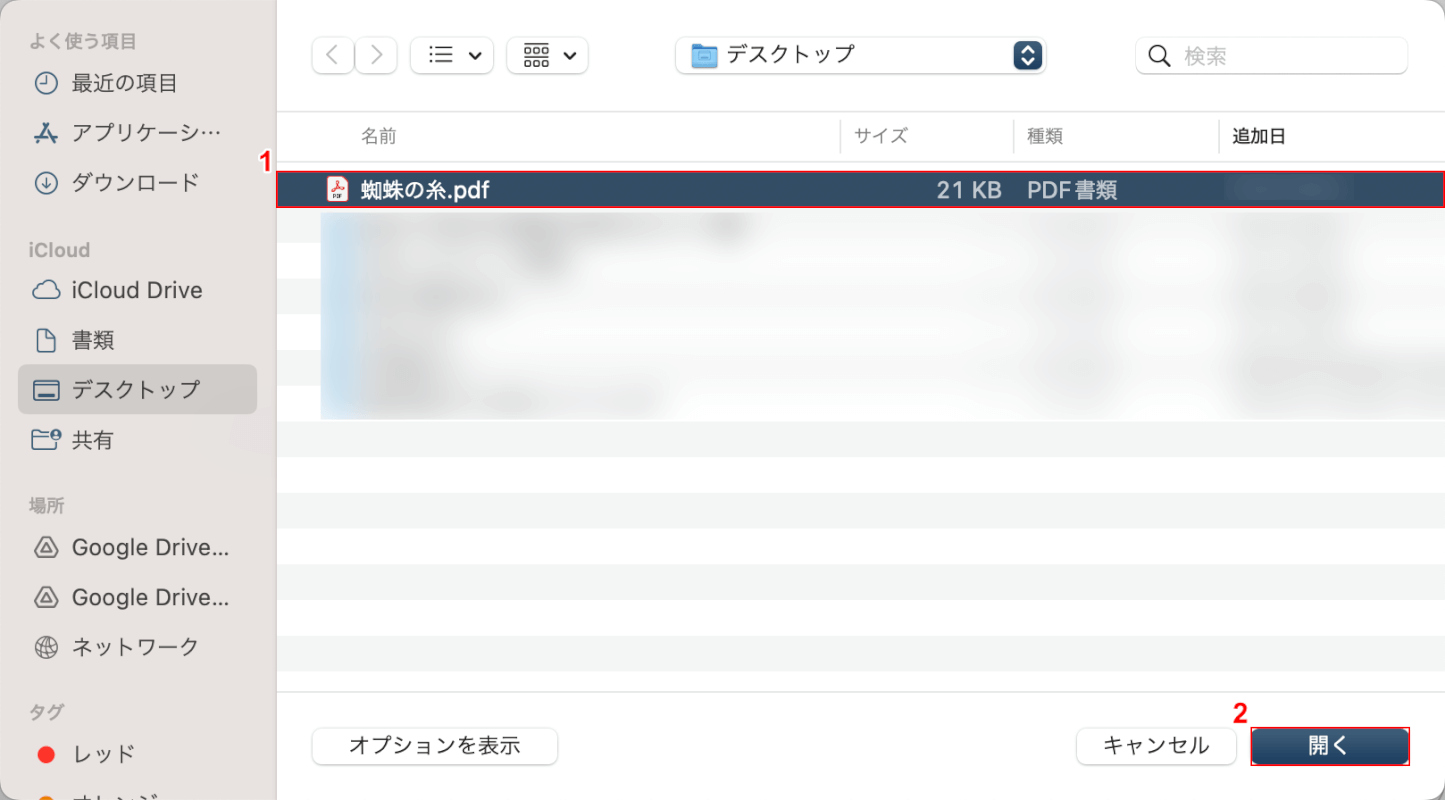
①OCR処理したいPDFファイル(例:蜘蛛の糸)を選択し、②「開く」ボタンを押します。
選択したPDFがアップロードされました。
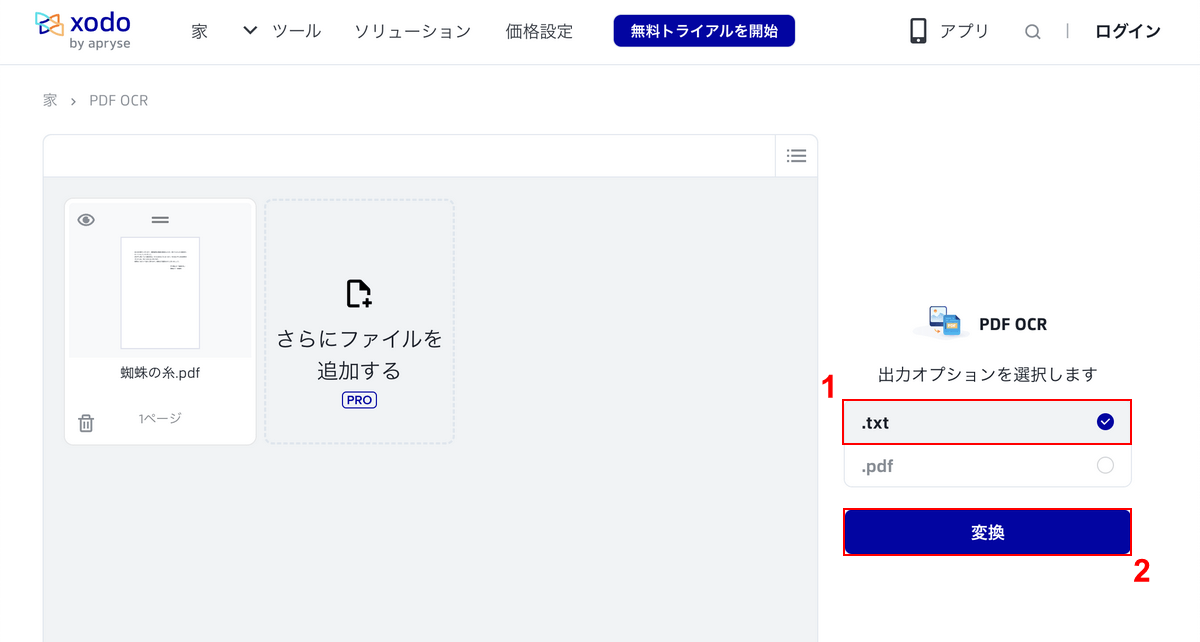
①出力オプションで任意の形式(例:.txt)を選択し、②「変換」ボタンを押します。
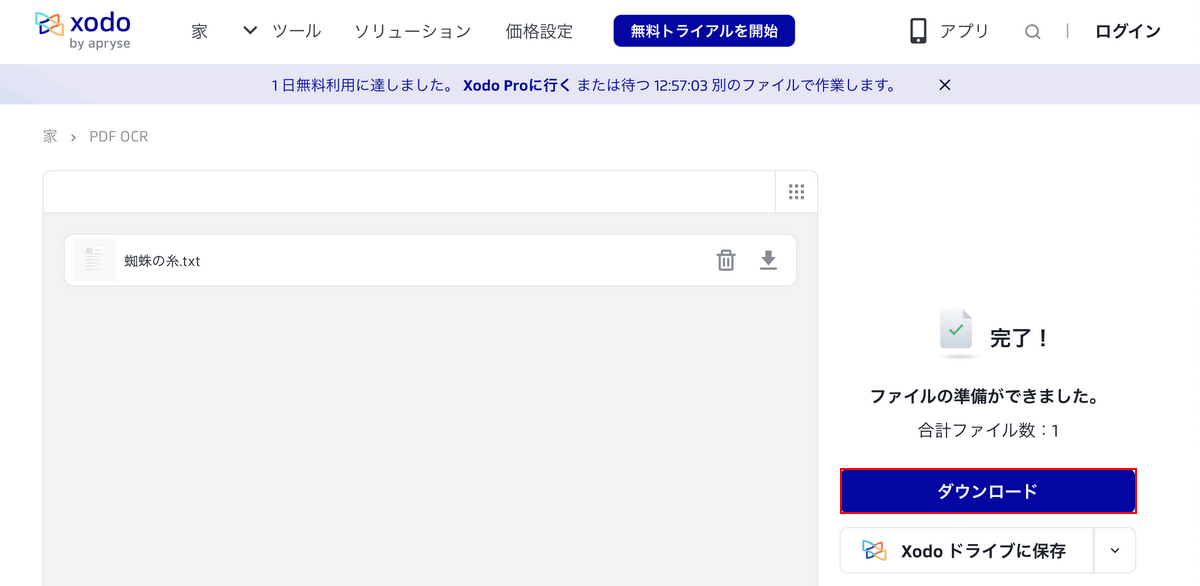
変換が完了すると、「完了!」が表示されます。
「ダウンロード」ボタンを押します。
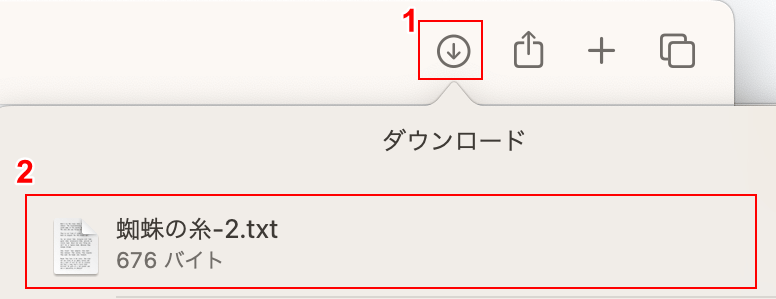
①ブラウザの「ダウンロード」ボタンを押し、②変換したファイル(例:蜘蛛の糸-2)を選択して開きます。
なお、上の画像はSafariで開いたものです。
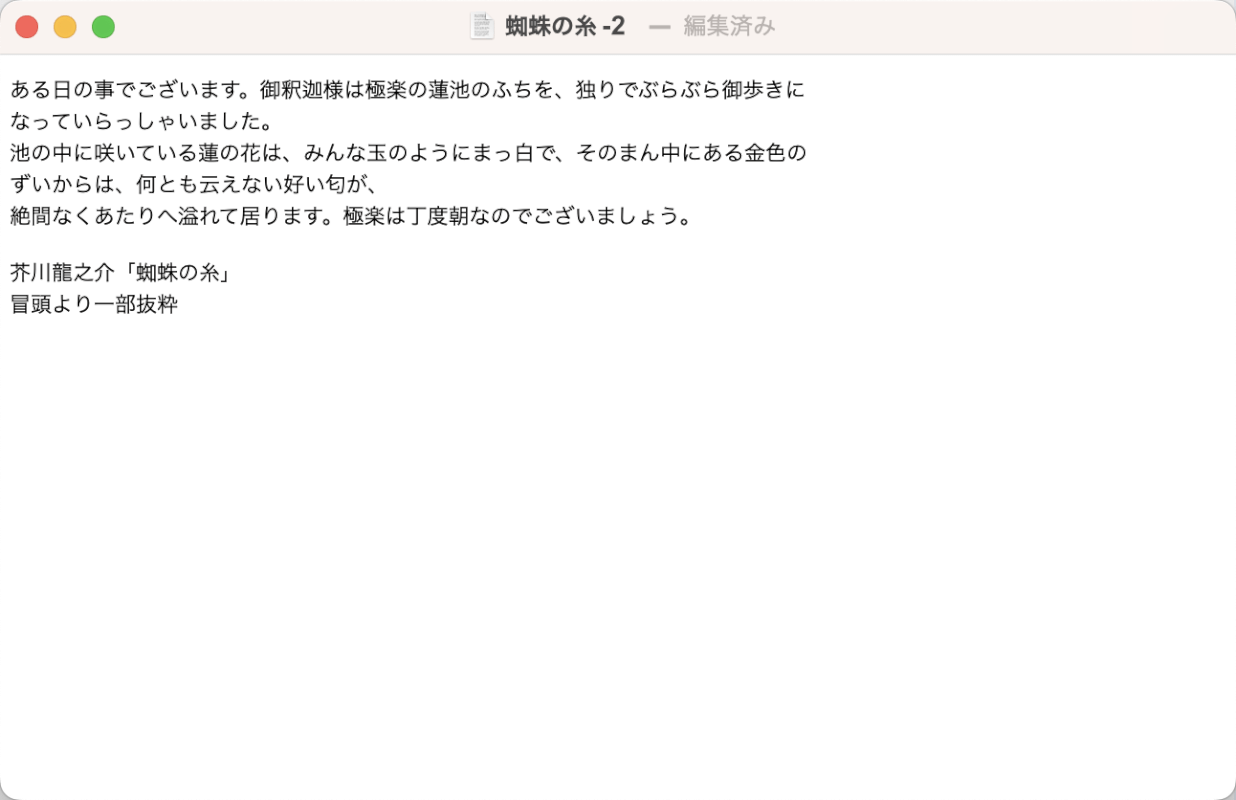
保存したtxt形式のファイルを開いて確認します。
上の画像のようにPDFをOCR処理することができました。
FineReader PDFの基本情報
FineReader PDF
日本語: 〇
オンライン(インストール不要): ×
オフライン(インストール型): 〇
FineReader PDFを使ってMacでPDFのOCR機能を利用する方法
FineReader PDFを使ってMacでPDFのOCR機能を利用する方法をご紹介します。
デスクトップ版はWindowsとMacに対応していますが、利用できる機能や料金が異なります。
無料版があり、7日間の試用期間中は有料版のすべての機能を利用できます。
今回はmacOS 14.1.1を使って、FineReader PDFのデスクトップ版でPDFのOCR機能を利用する方法をご紹介します。
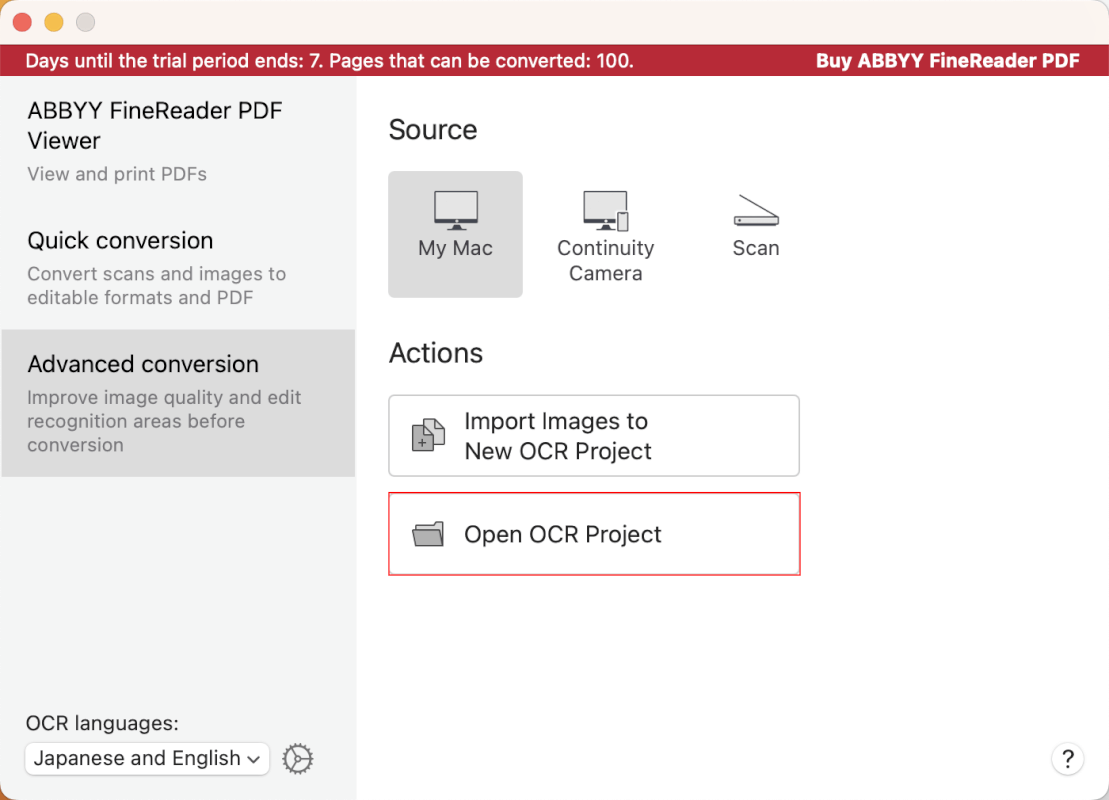
FineReader PDFを起動します。
「Open OCR Project」を選択します。
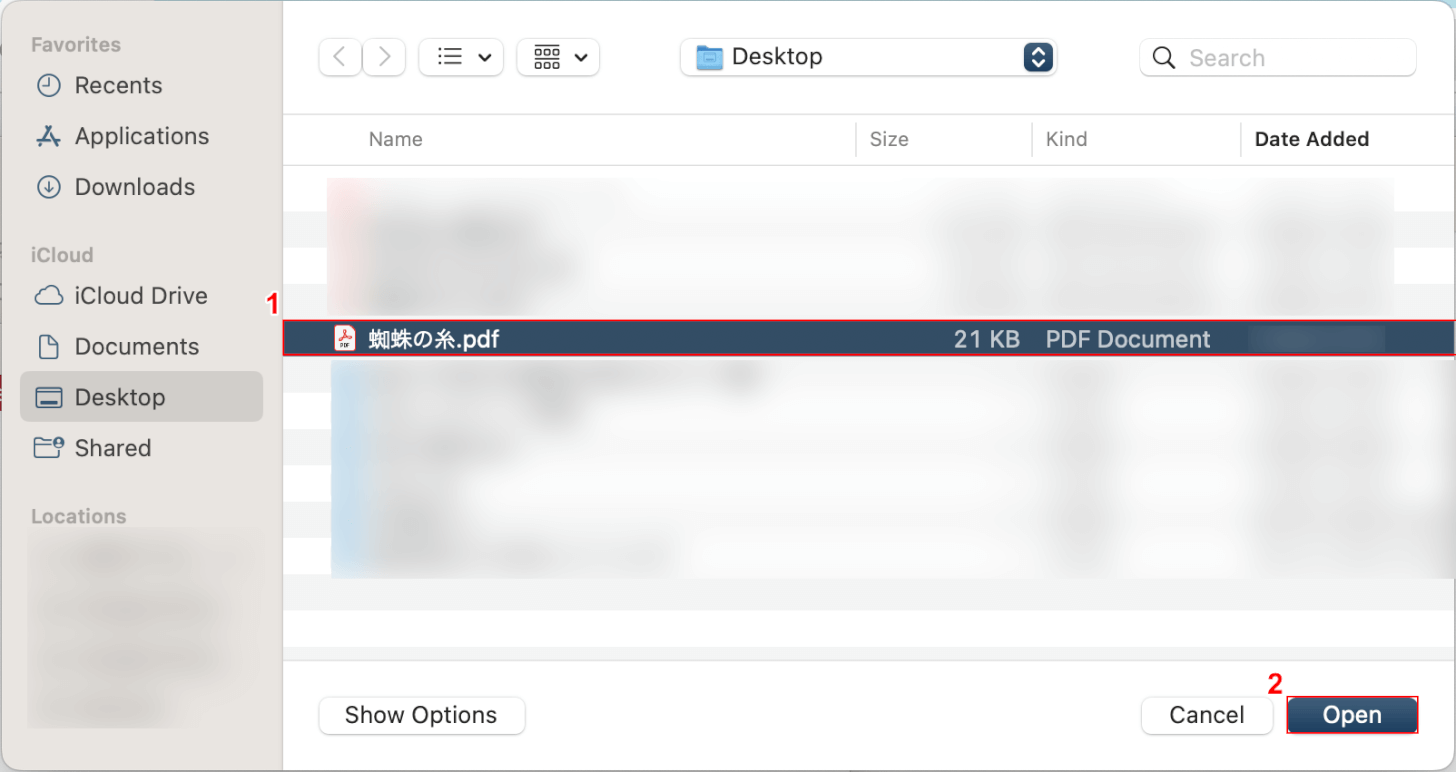
①OCR処理したいPDFファイル(例:蜘蛛の糸)を選択し、②「Open」ボタンを押します。
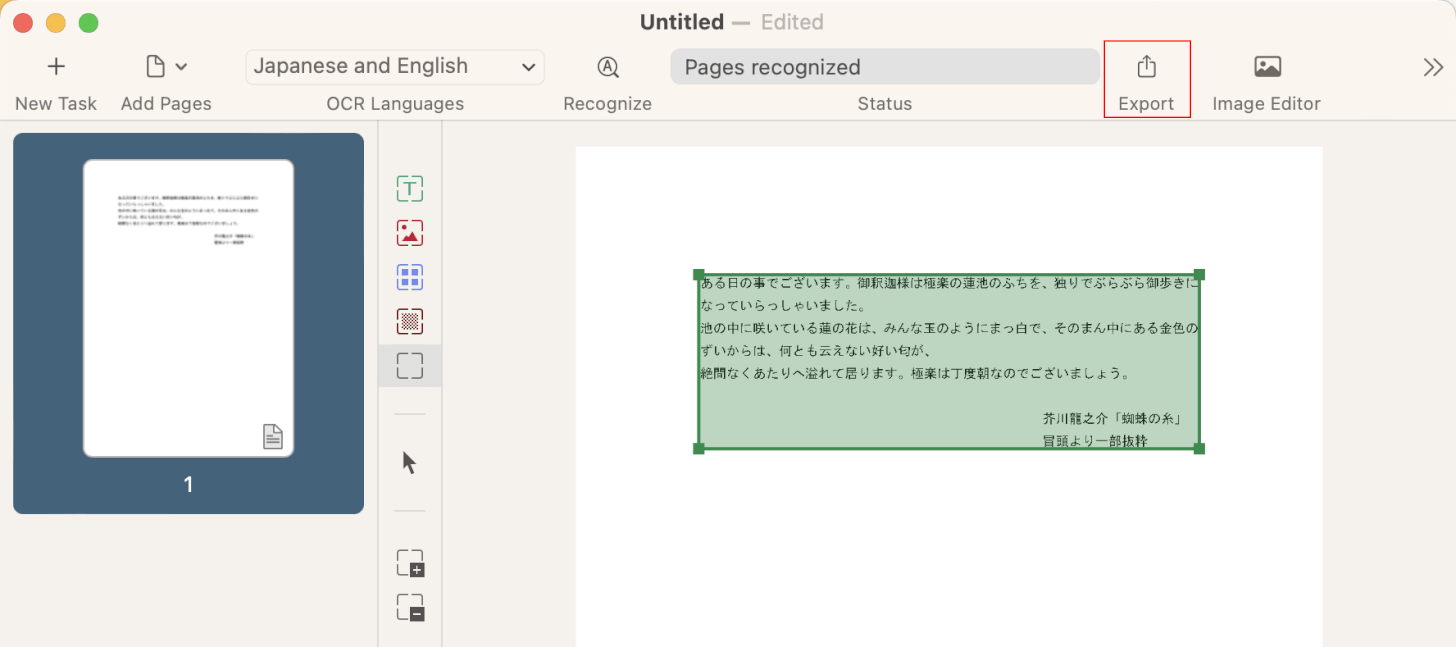
「Export」を選択します。
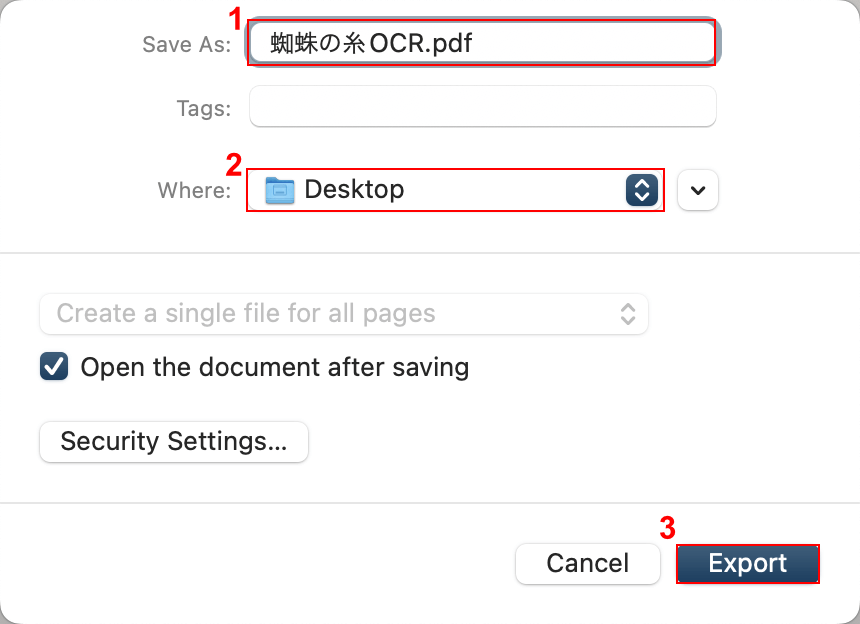
①任意のファイル名(例:蜘蛛の糸OCR)を入力し、②任意の格納場所(例:Desktop)を選択します。
③「Export」ボタンを押します。
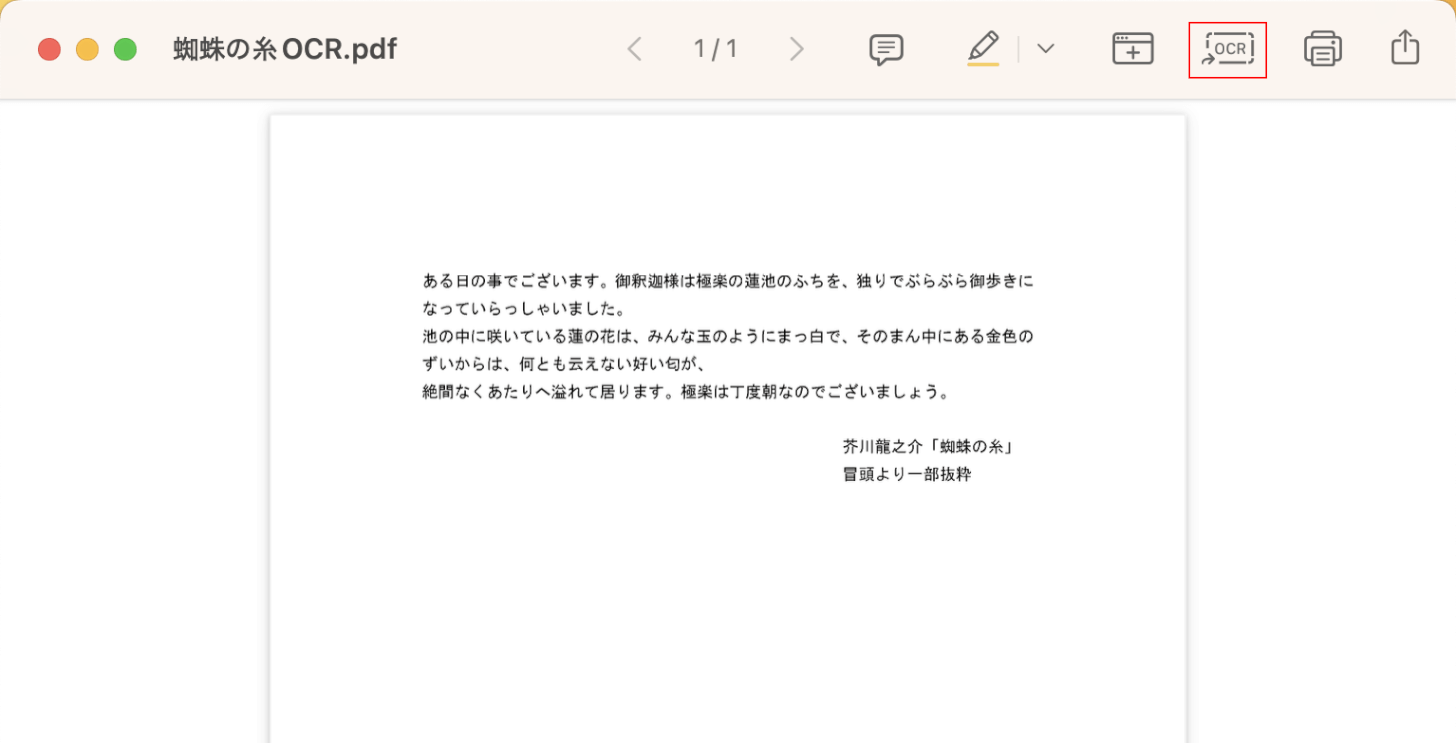
上の画像の表示に切り替わります。
「OCR」ボタンを押します。
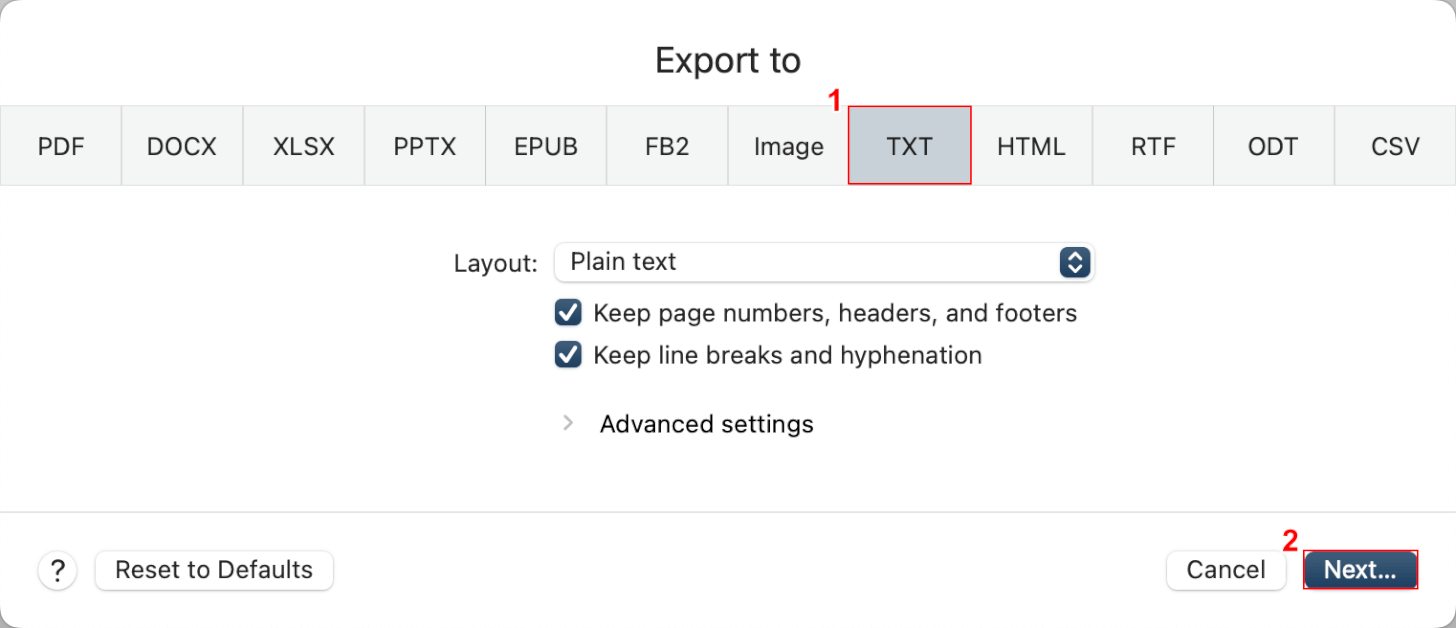
①OCR処理後のファイル形式(例:TXT)を選択し、②「Next」ボタンを押します。
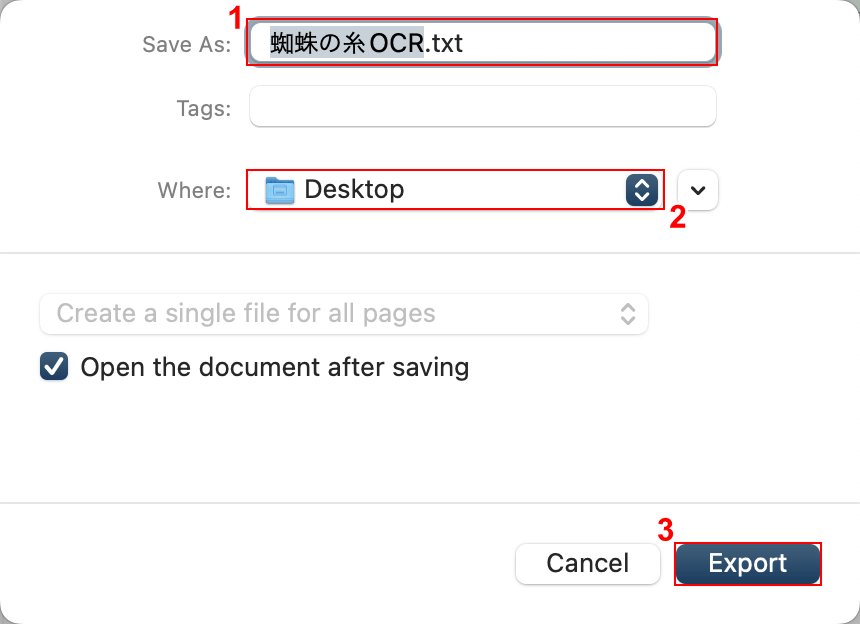
①任意のファイル名(例:蜘蛛の糸OCR)を入力し、②任意の格納場所(例:Desktop)を選択します。
③「Export」ボタンを押します。

保存したtxt形式のファイルを開いて確認します。
上の画像のようにPDFをOCR処理することができました。
問題は解決できましたか?
記事を読んでも問題が解決できなかった場合は、無料でAIに質問することができます。回答の精度は高めなので試してみましょう。
- 質問例1
- PDFを結合する方法を教えて
- 質問例2
- iLovePDFでできることを教えて
コメント
この記事へのコメントをお寄せ下さい。