
- 公開日:
PDFのOCR(テキスト変換)に高精度なフリーソフト3選
PDFのテキスト変換、すなわちOCR(光学文字認識)機能を持つフリーソフトは、文書作業の効率を大幅に向上させることができます。
そこで今回は、高精度なOCR機能があるおすすめの無料ソフトを3つ紹介します。
ご紹介するソフトを活用すれば、手軽に文書のデジタル化が進められ、作業の幅が広がることでしょう。
PDF24 Creatorの基本情報
日本語: 〇
オンライン(インストール不要): 〇
オフライン(インストール型): 〇
PDF24 CreatorでPDFのOCR(テキスト変換)処理を行う方法
PDF24 Creatorには「PDF OCR」という機能があり、PDFをアップロードするだけでOCRによるテキスト変換ができます。
完全無料かつ無制限で使用できるため、気軽に使用できます。オンライン版とデスクトップ版がありますが、どちらでもOCR機能は使えます、
詳しい使い方は以下の通りです。PDF24 Creatorのデスクトップ版を使用しています。
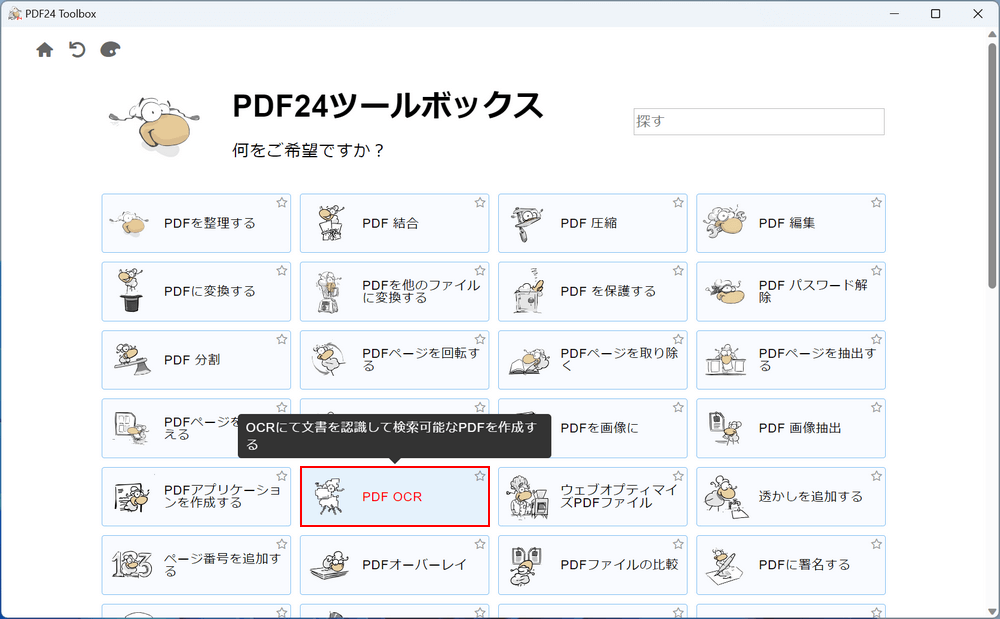
PDF24 Creatorを開き、「PDF OCR」を選択します。
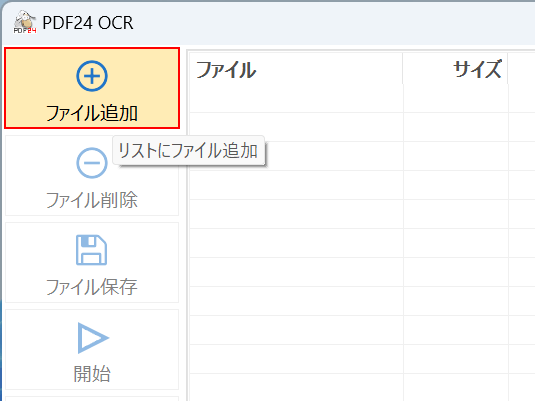
「ファイル追加」ボタンを押します。
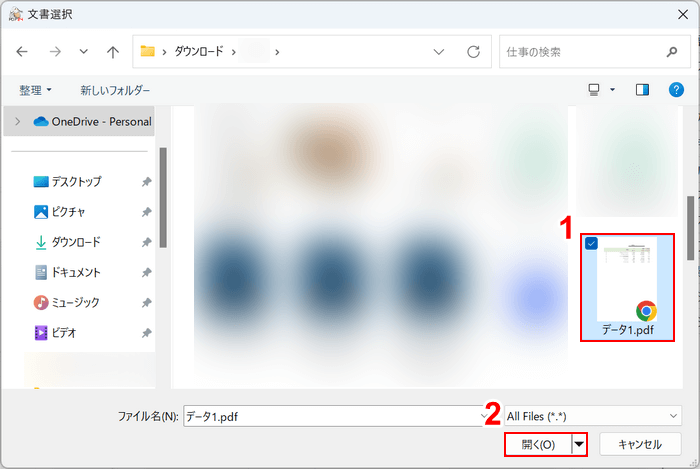
「文書選択」ダイアログボックスが表示されます。
①OCR処理したいPDF(例:データ1.pdf)を選択し、②「開く」ボタンを押します。
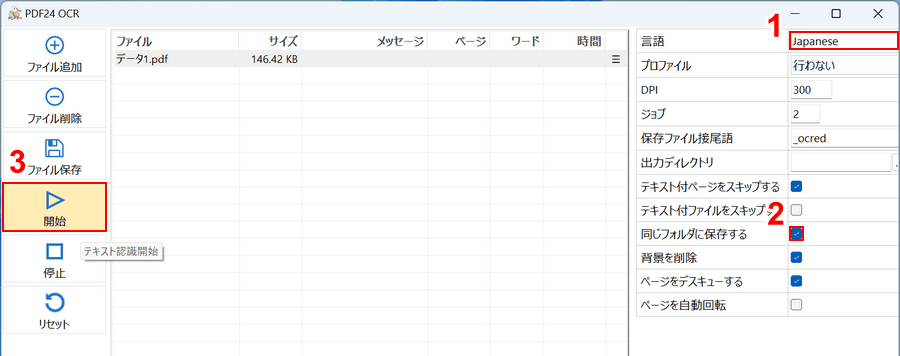
①読み取る言語(例:Japanese)を選択します。
②保存をスムーズにするため、「同じフォルダに保存する」にチェックを入れます。
③各設定を調整できたら、「開始」ボタンを押します。
「時間」の項目にチェックマークが表示されたら、OCR処理完了です。
保存できているか確認してみましょう。
エクスプローラーを起動し、アップロードしたPDFと同じフォルダを開きます。
すると、PDF24 CreatorでOCR処理をしたデータが保存されていることが分かります。
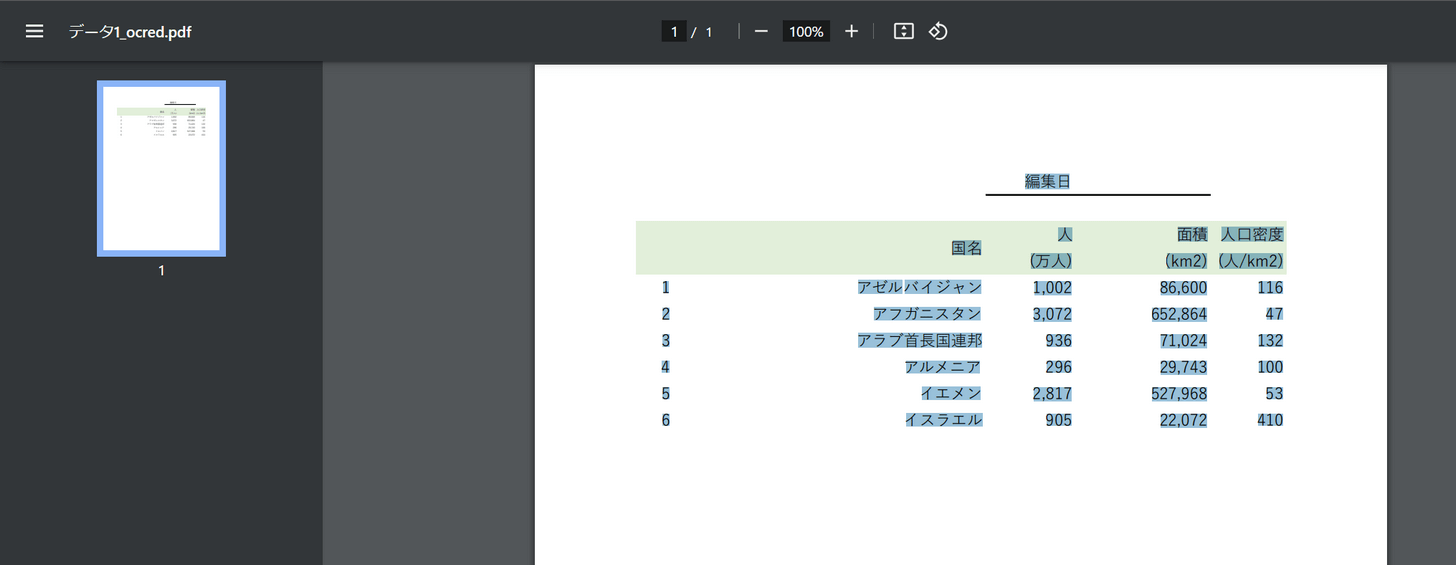
PDF24 Creatorでは、OCR後のデータはPDFとして出力されます。
PDFを開いてテキストをドラッグしてみると、テキスト部分が認識されて範囲選択できるようになっています。
Sejdaの基本情報
Sejda
日本語: 〇
オンライン(インストール不要): 〇
オフライン(インストール型): 〇
SejdaでPDFのOCR(テキスト変換)処理を行う方法
Sejdaのデスクトップ版では、PDFをアップロードするだけでテキストデータを簡単に抽出できます。
無料では「1日に3回まで」使用可能です。出力する形式をPDF/テキストファイル(.txt)の2つから選べるためおすすめです。
詳しい使い方は以下の通りです。Sejdaのデスクトップ版を使用しています。
Sejdaを開き、「OCR」を選択します。
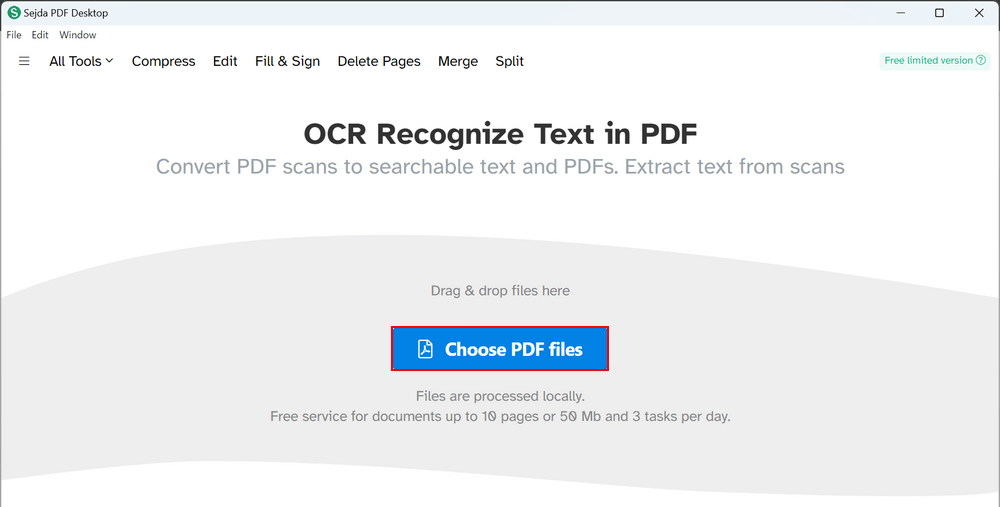
「Choose PDF files」ボタンを押します。
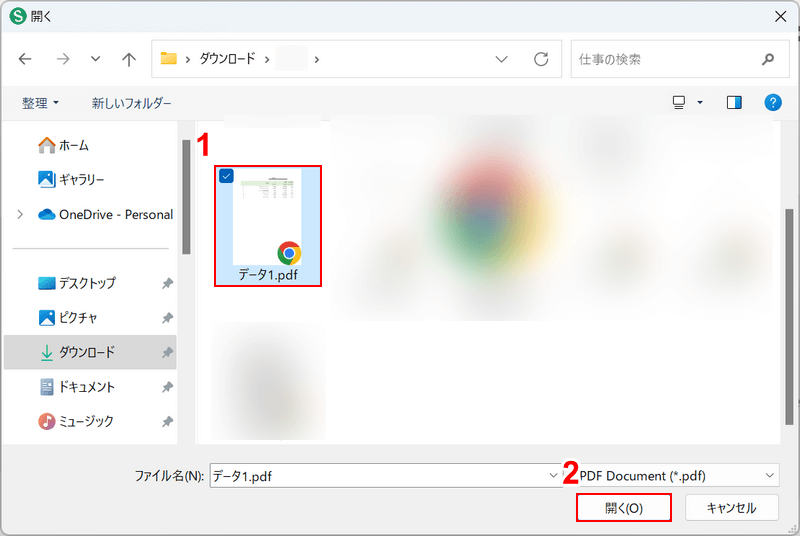
「開く」ダイアログボックスが表示されます。
①OCR処理したいPDF(例:データ1.pdf)を選択し、②「開く」ボタンを押します。
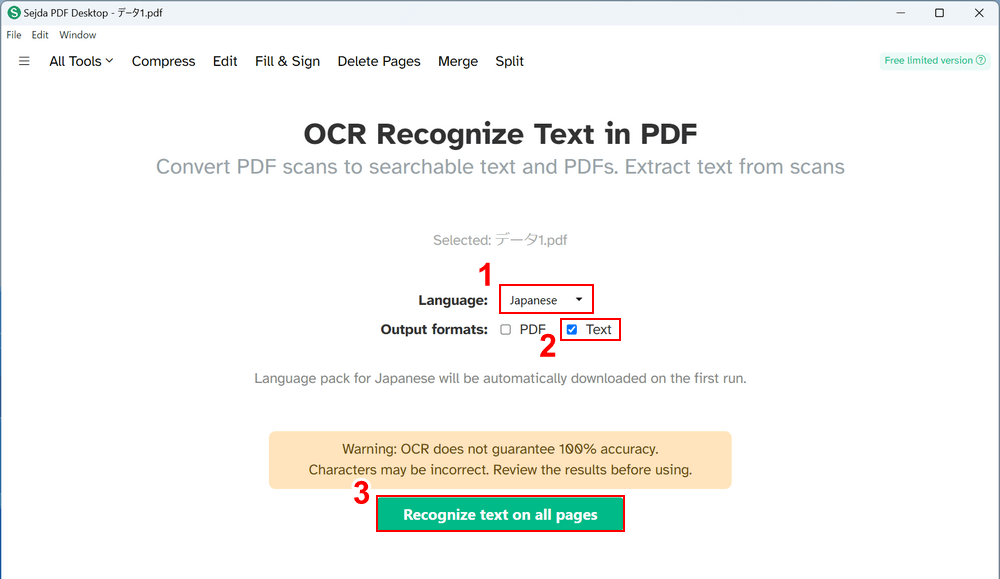
①読み取る言語(例:Japanese)を選択し、②出力するファイル形式(例:Text)を選択します。
③設定できたら、「Recognize text on all pages」ボタンを押します。
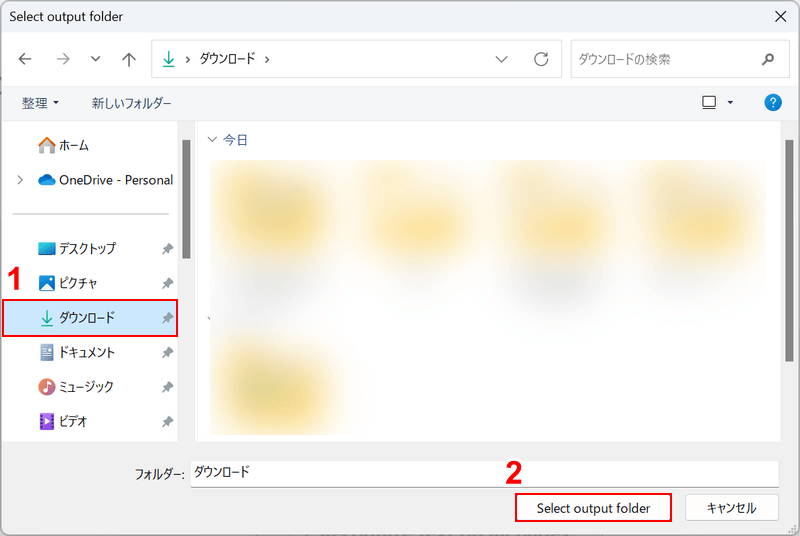
「Select output folder」ダイアログボックスが表示されます。
①任意の保存先(例:ダウンロード)を選択し、②「Select output folder」ボタンを押します。
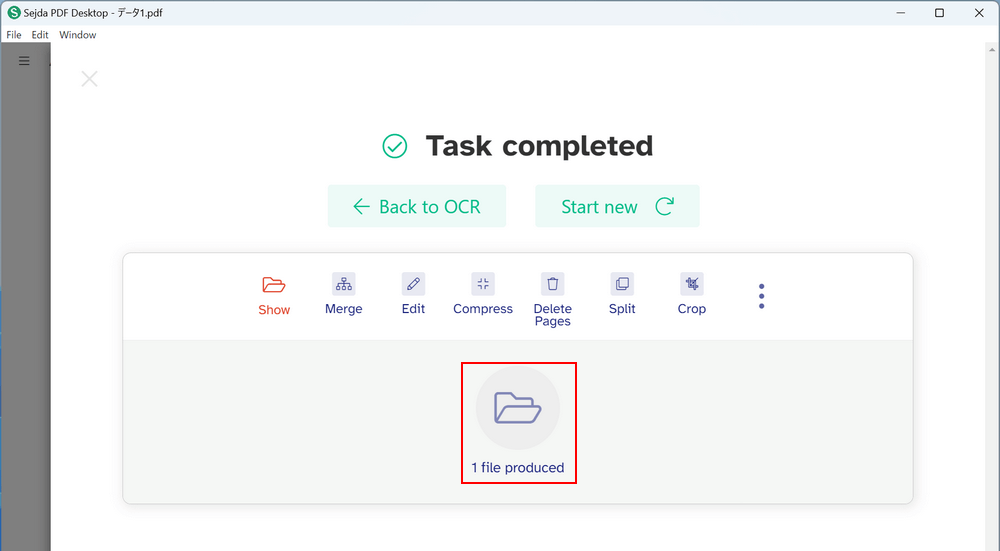
「Task completed」という画面が表示されたら、OCR処理は完了です。
出力されたファイルを確認するため、「1 file produced」を選択します。
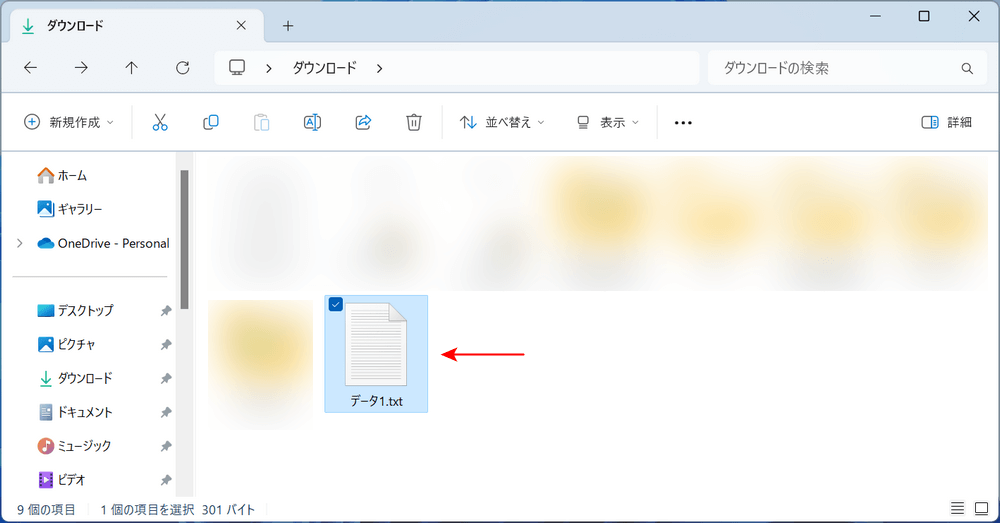
出力されたファイルが保存されていることを確認できます。
今回は出力形式をTextに指定したため、テキストファイル(.txt)として出力されました。
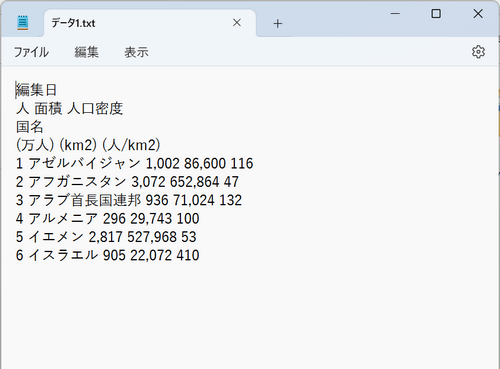
試しにテキストファイルを開いてみました。
データは比較的見やすくまとまっています。間違いもなく、正確に抽出されています。
CamScannerの基本情報
CamScanner
- 無料のお試しを押したら12000円決済になってしまった。
日本語: ×
オンライン(インストール不要): 〇
オフライン(インストール型): 〇
CamScannerでPDFのOCR(テキスト変換)処理を行う方法
CamScannerでは、アップロードしたPDFのテキストデータのみを抽出してテキストファイル(txt)として保存できます。
無料版だと「3回まで」OCR機能を使用できます。4回目以降の使用は有料版に加入する必要があります。
詳しい使い方は以下の通りです。CamScannerのスマホアプリ版(iOS)を使用しています。
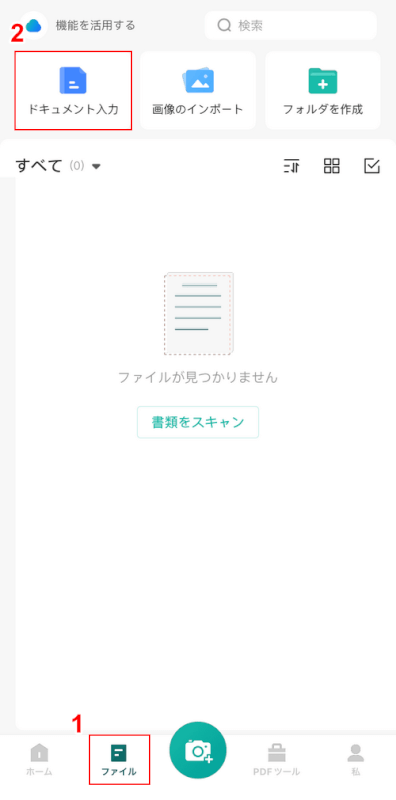
CamScannerを開き、①「ファイル」、②「ドキュメント入力」の順に選択します。
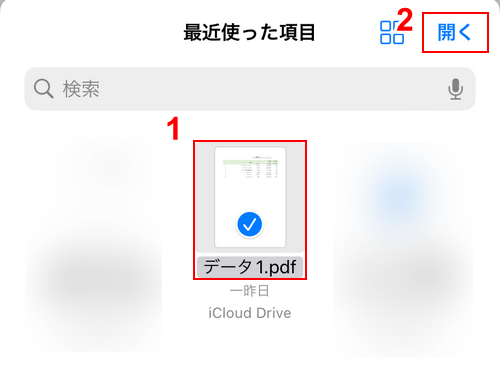
①OCR処理したいPDF(例:データ1.pdf)、②「開く」の順に選択します。
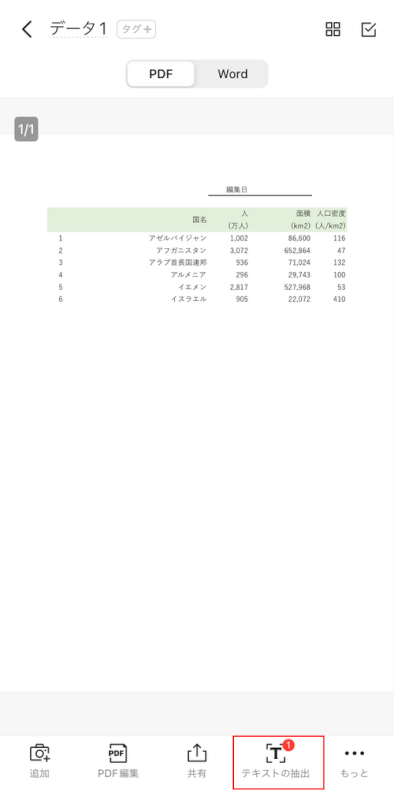
「テキストの抽出」を選択します。
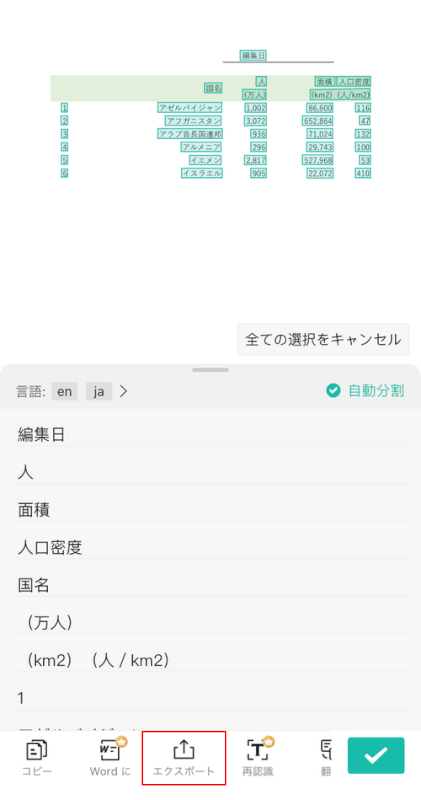
テキストデータが抽出されていることが分かります。
テキストデータを保存するため、「エクスポート」を選択します。
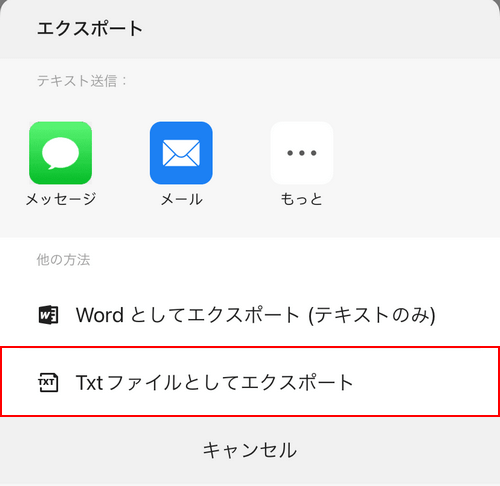
「Txtファイルとしてエクスポート」を選択します。
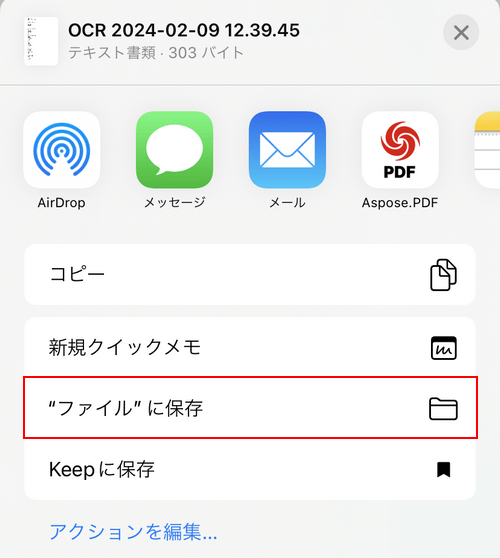
「"ファイル"に保存」を選択します。
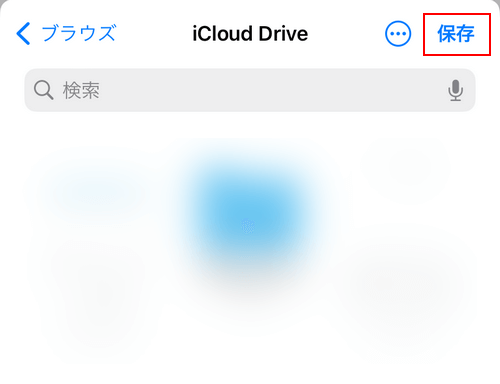
「保存」を選択します。
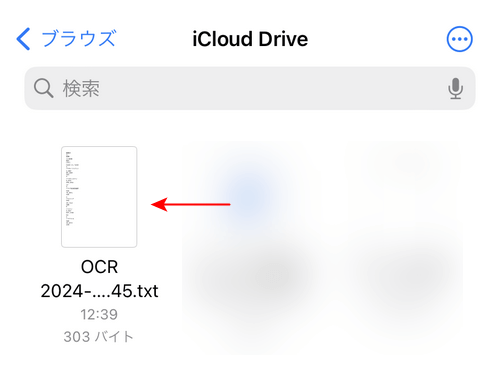
スマホのファイルアプリを開くと、CamScannerで抽出したテキストデータのファイルが保存されていることを確認できます。

試しにテキストファイルを開いてみました。
表の形は保っていませんが、正確に文字を読み取って抽出されています。
問題は解決できましたか?
記事を読んでも問題が解決できなかった場合は、無料でAIに質問することができます。回答の精度は高めなので試してみましょう。
- 質問例1
- PDFを結合する方法を教えて
- 質問例2
- iLovePDFでできることを教えて
コメント
この記事へのコメントをお寄せ下さい。