
- 公開日:
オフラインで利用できるPDFのOCRフリーソフト3選
OCRによりPDFファイルの内容をテキストデータとして抽出することで、複製や編集、検索が容易になります。
また、PDFファイルのテキストを手入力しなおす必要がなくなり、大量のデータを効率的にテキスト化することが可能です。
この記事では、ソフトをデバイスにインストールし、オフラインでPDFをOCR処理できる無料ソフトをご紹介します。
PDF24 Creatorの基本情報
日本語: 〇
オンライン(インストール不要): 〇
オフライン(インストール型): 〇
PDF24 CreatorでPDFのOCR処理を行う方法
PDF24 CreatorでPDFのOCR処理を行う方法をご紹介します。
PDF24 Creatorは有料版はなく、すべて完全に無料で利用できます。
無料で利用する際の制限もありません。また、PDFのフラット化やオーバーレイなどの高度な操作が利用できるツールも無料で使えます。
今回はWindows 11を使って、PDF24 Creatorのデスクトップ版でPDFのOCRを行う方法をご紹介します。
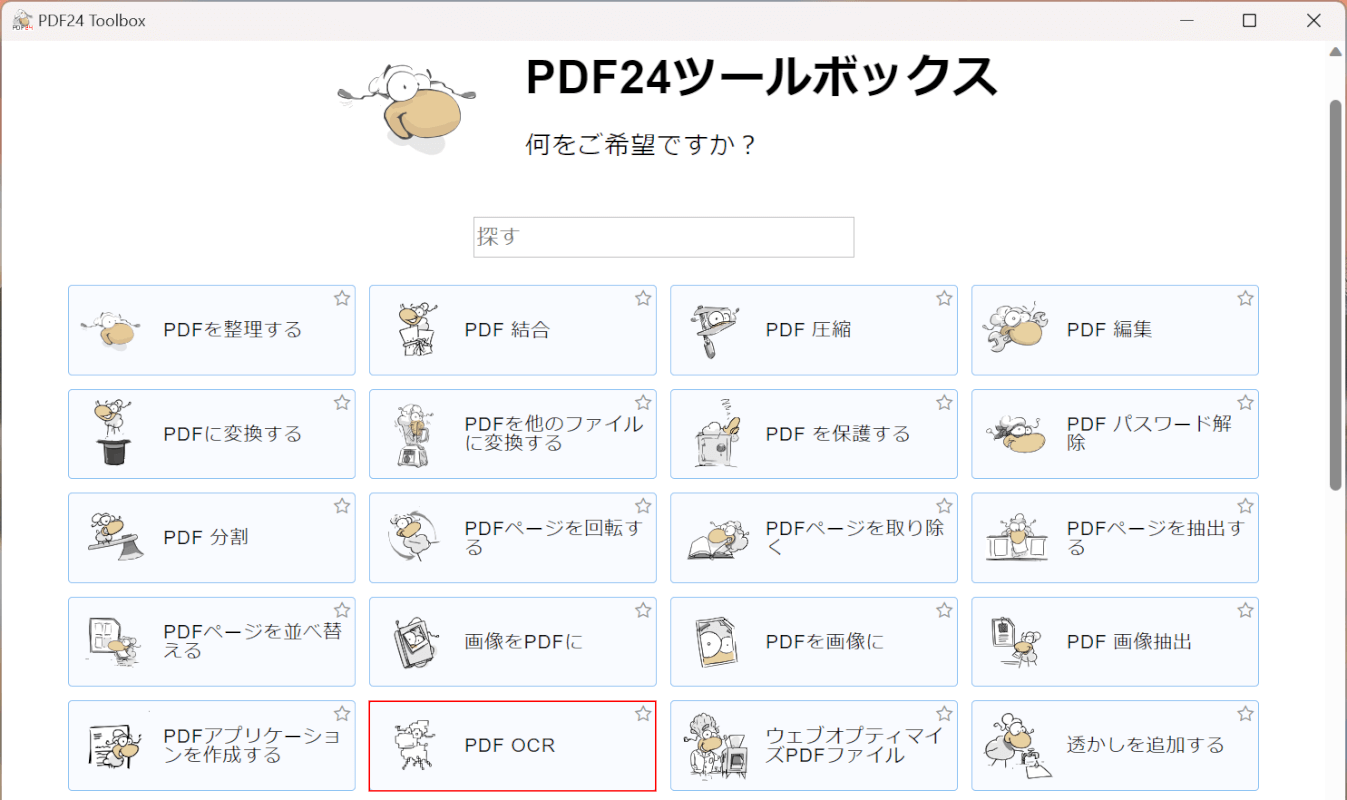
PDF24 Creatorを起動します。
「PDF OCR」を選択します。
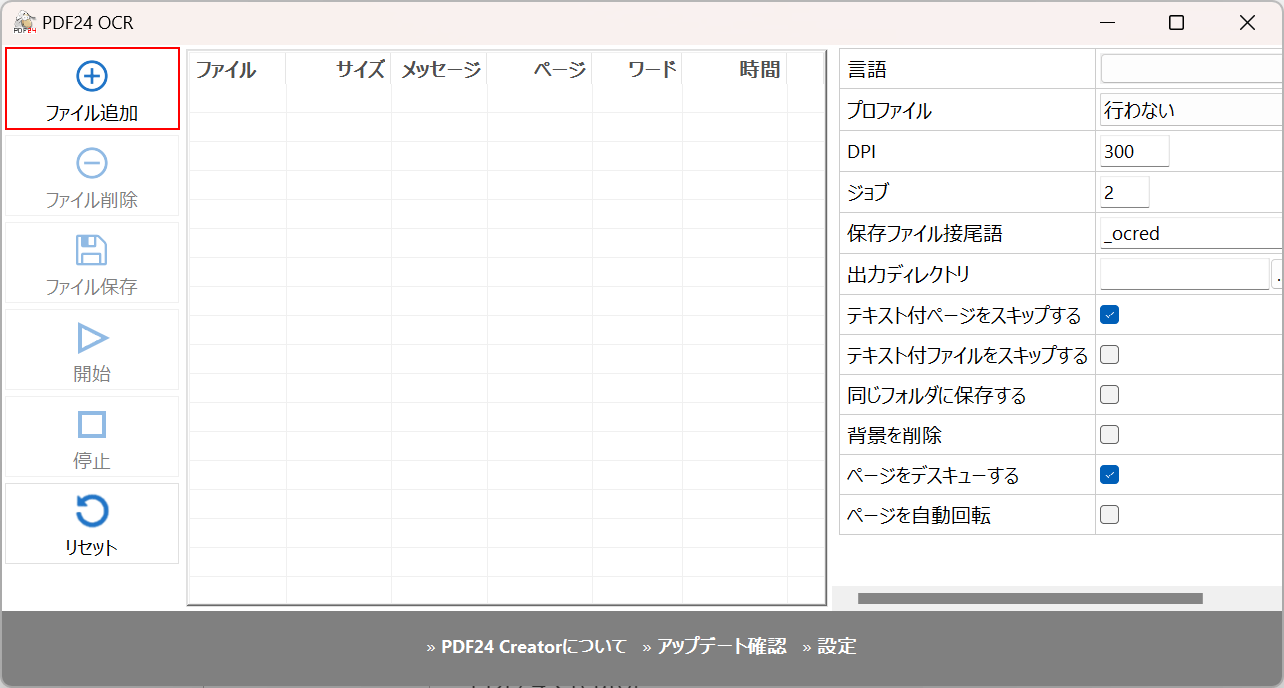
上記の画面が表示されます。
「ファイル追加」を選択します。
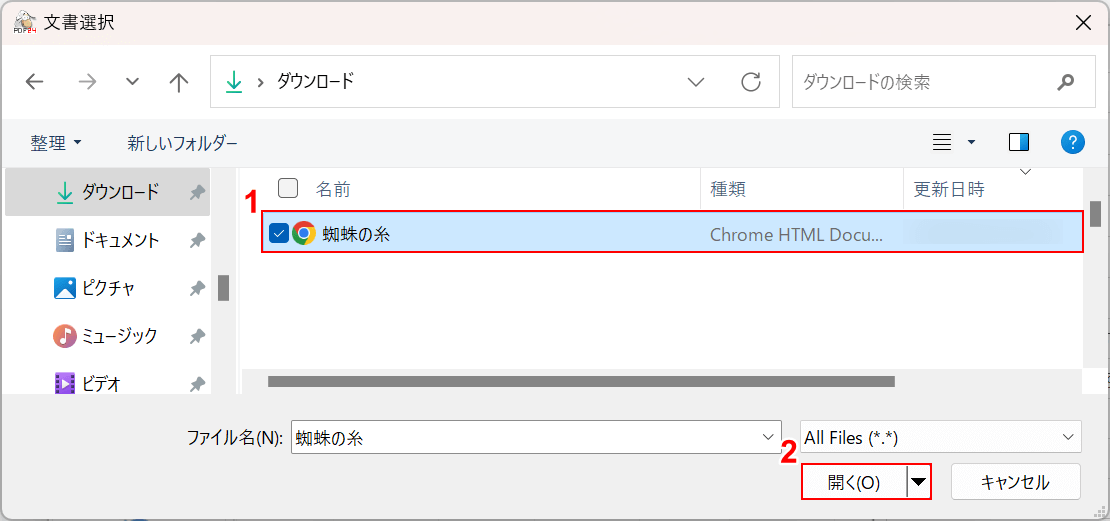
「文書選択」ダイアログボックスが表示されます。
①OCR処理したいPDFファイル(例:蜘蛛の糸)を選択し、②「開く」ボタンを押します。
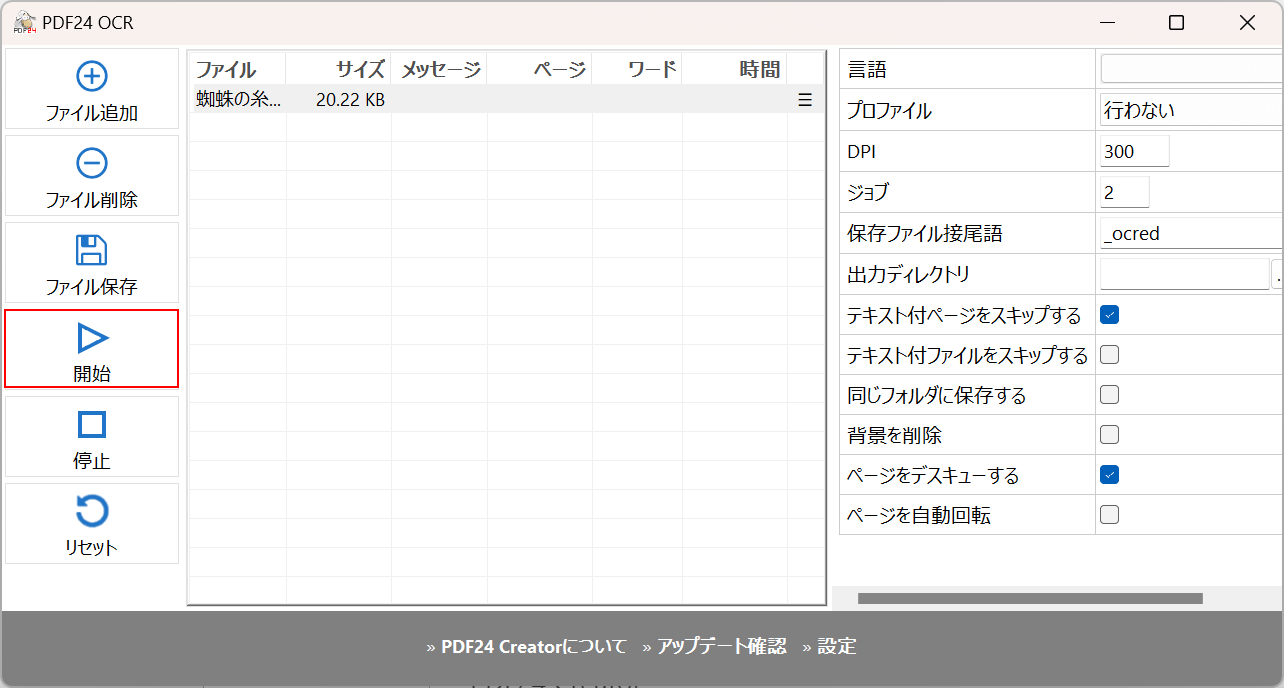
「開始」を選択します。
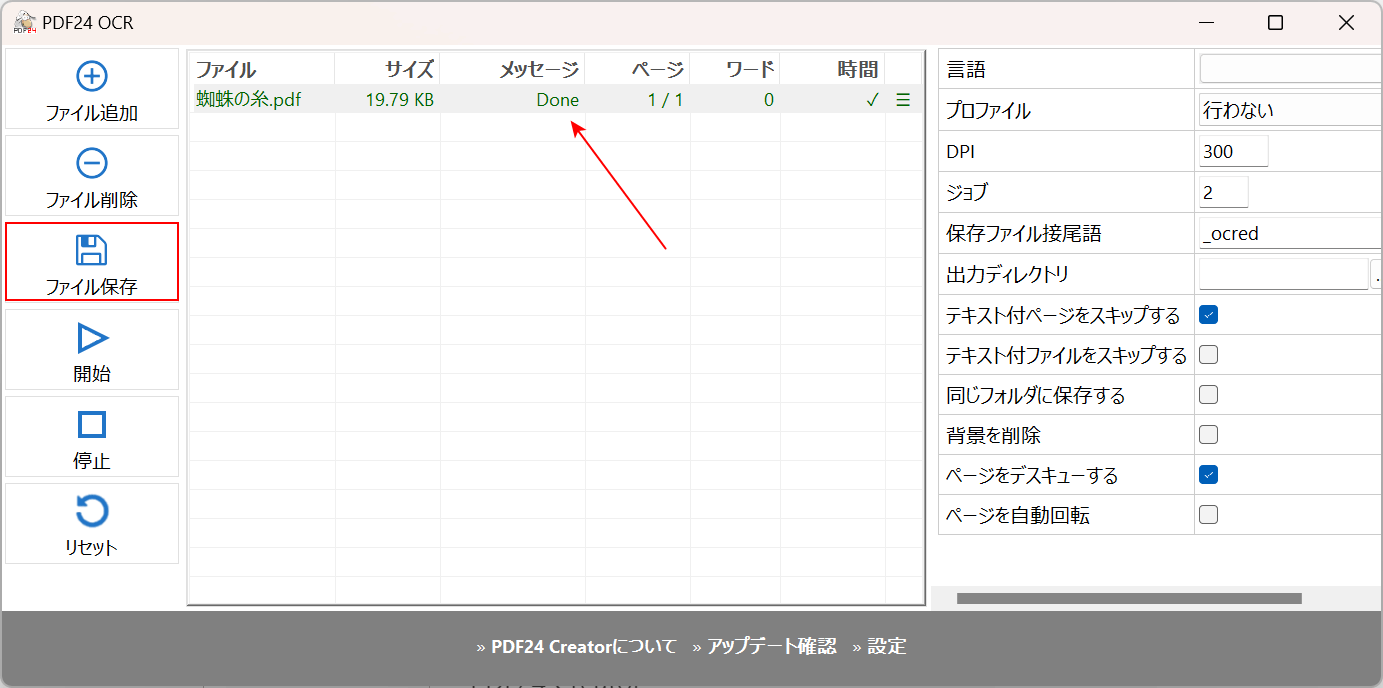
「メッセージ」の項目が赤矢印で示す通り「Done」になればOCR処理が完了したことになります。
「ファイル保存」を選択します。
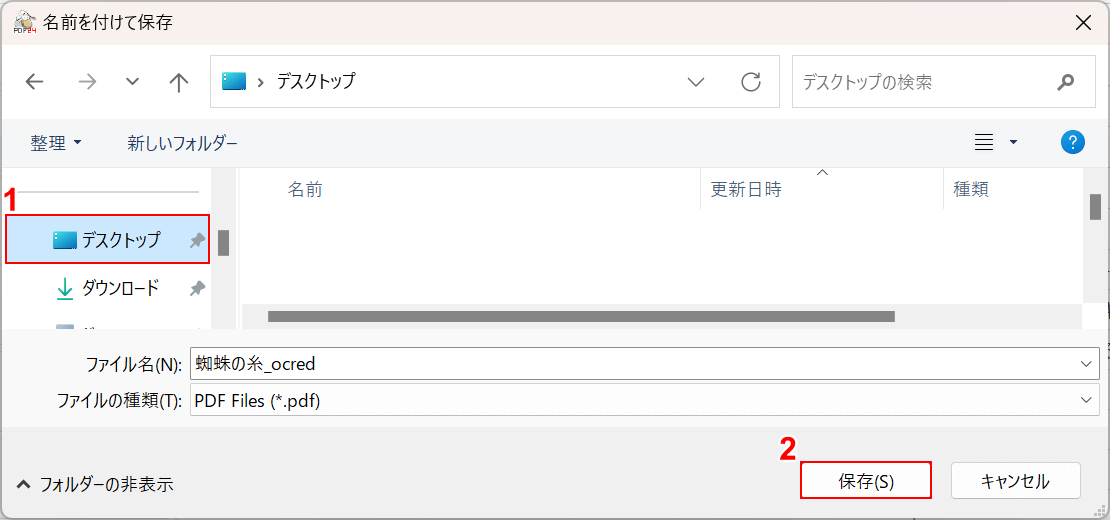
「名前を付けて保存」ダイアログボックスが表示されます。
①任意の格納場所(例:デスクトップ)を選択し、②「保存」ボタンを押します。
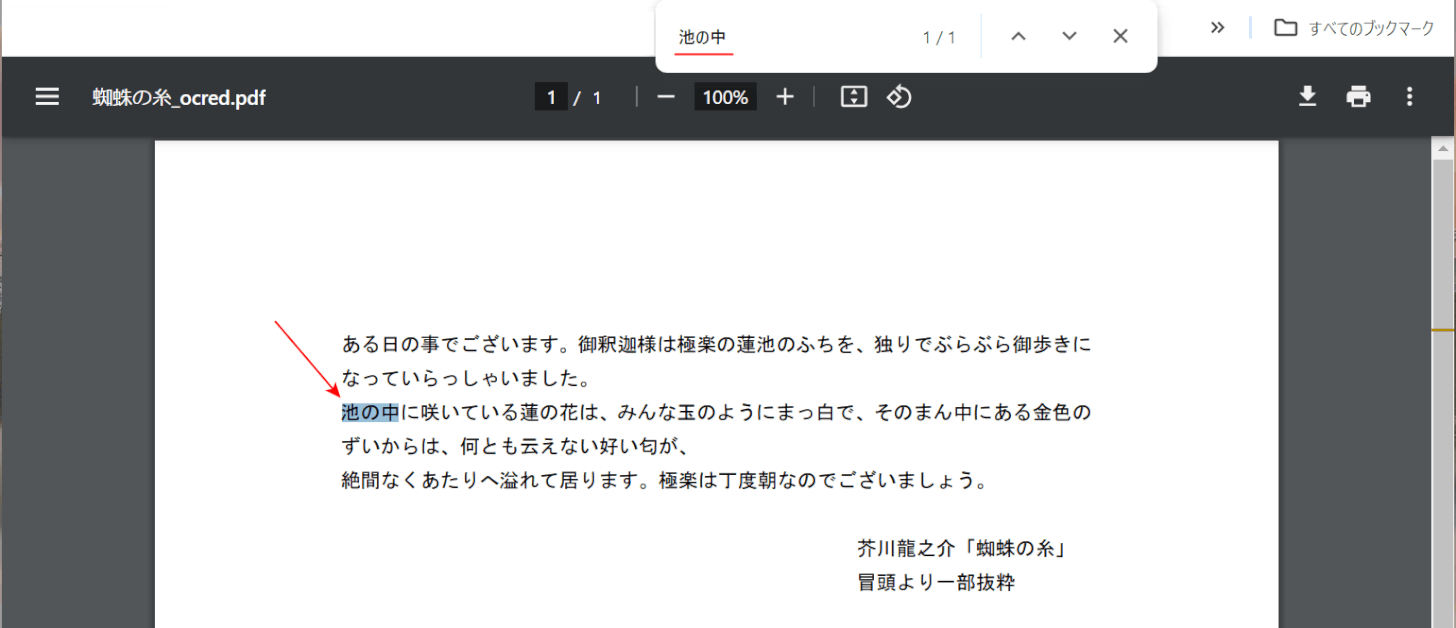
赤矢印で示す通り、テキスト検索をするとテキストを認識していることが確認できます。
オフラインでPDFをOCR処理することができました。
Sejdaの基本情報
Sejda
日本語: 〇
オンライン(インストール不要): 〇
オフライン(インストール型): 〇
SejdaでPDFのOCR処理を行う方法
SejdaでPDFのOCR処理を行う方法をご紹介します。
無料版はファイルサイズやファイル数に制限はありますが、有料版のすべての機能を使用することができます。
また、アカウント登録やクレジットカードの登録など不要でインストール後はすぐ利用できます。
今回はWindows 11を使って、Sejdaのデスクトップ版でPDFのOCRを行う方法をご紹介します。
Sejdaを起動します。
「OCR」を選択します。
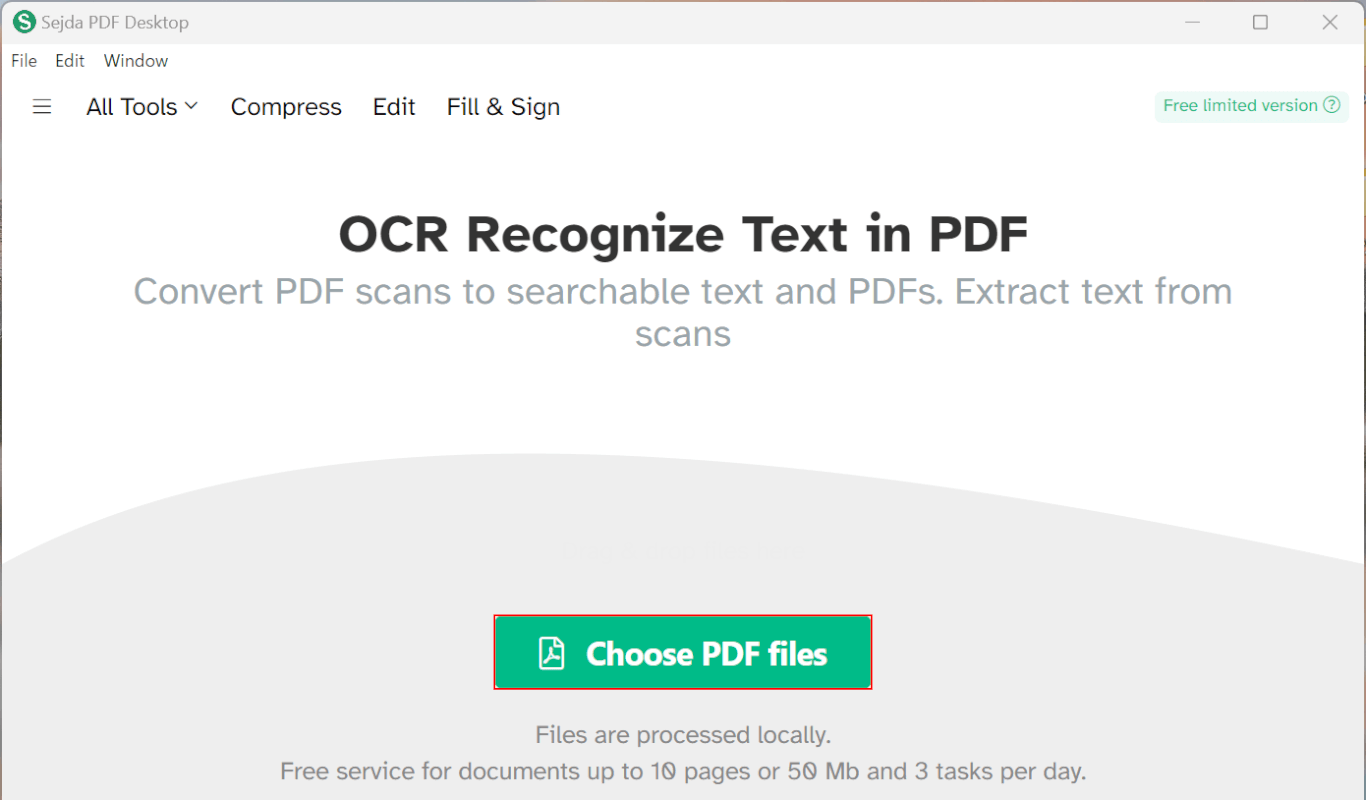
「Choose PDF files」ボタンを押します。
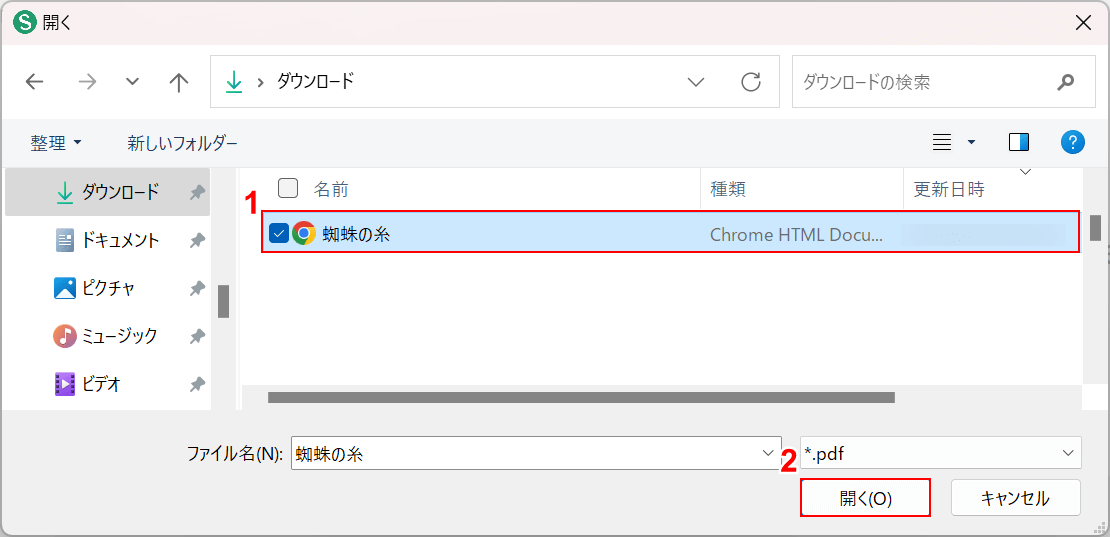
「開く」ダイアログボックスが表示されます。
①OCR処理したいPDFファイル(例:蜘蛛の糸)を選択し、②「開く」ボタンを押します。
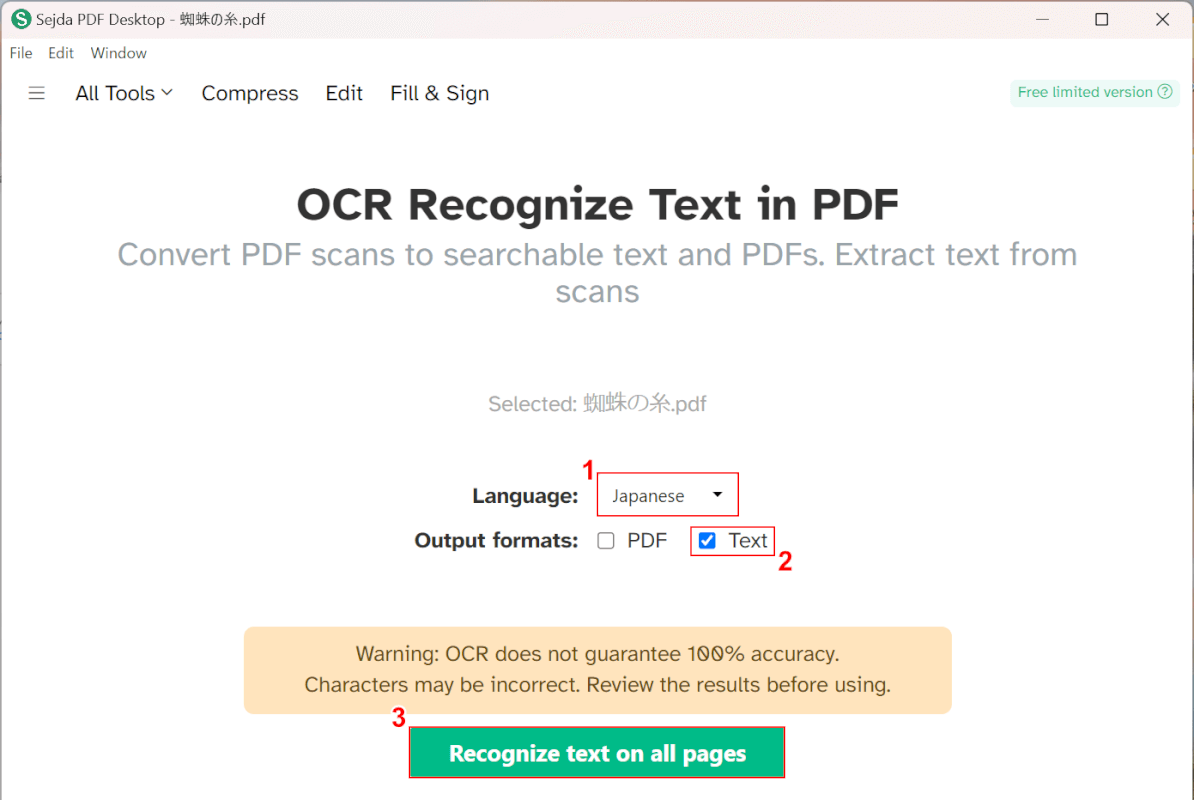
①Languageで任意の言語(例:Japanese)を選択し、②Output formatsで任意のファイル形式(例:Text)にチェックを入れます。
③「Recognize text on all pages」ボタンを押します。
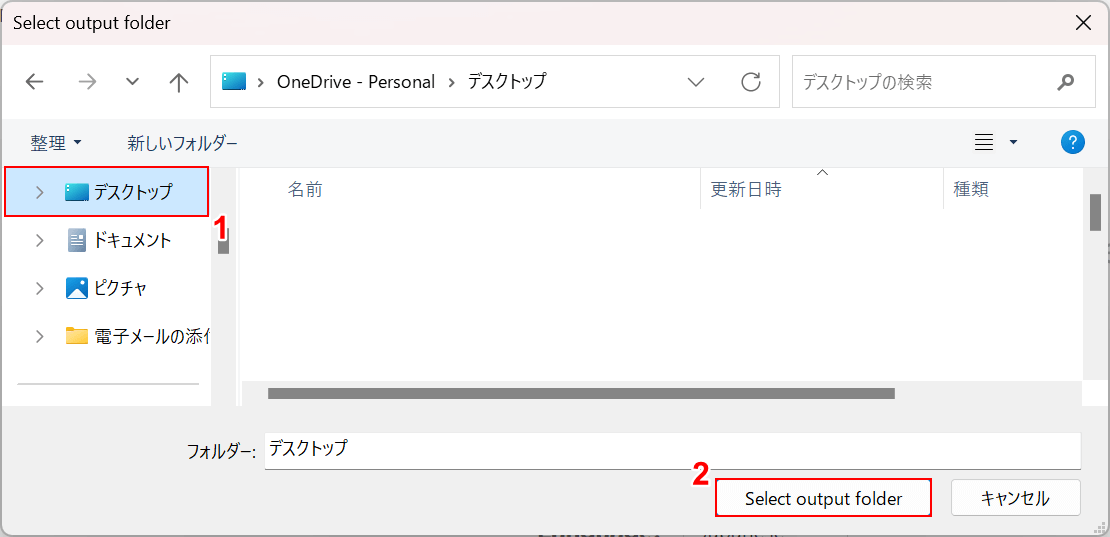
「Select output folder」ダイアログボックスが表示されます。
①任意の格納場所(例:デスクトップ)を選択し、②「Select output folder」ボタンを押します。
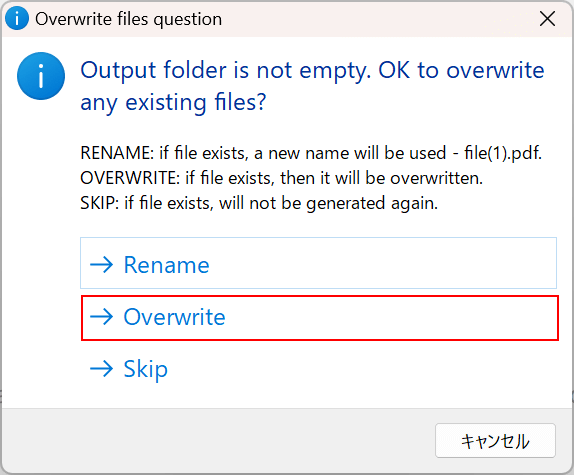
上記のポップアップが表示されるので、任意の保存形式(例:Overwrite)を選択します。
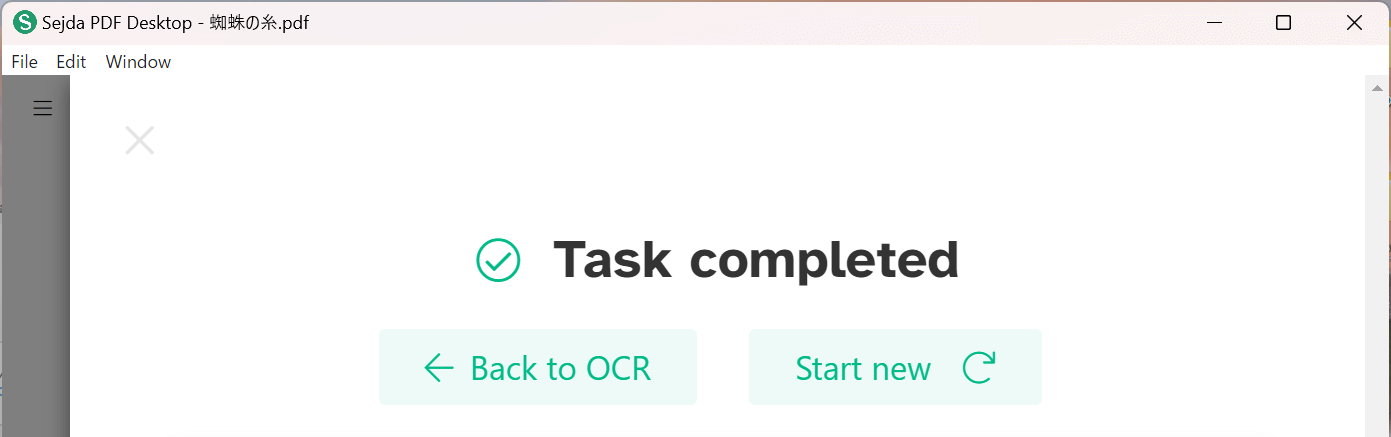
変換が完了されると上記の画面が表示されます。
先ほど選択した保存場所にOCR処理後のファイルが保存されます。
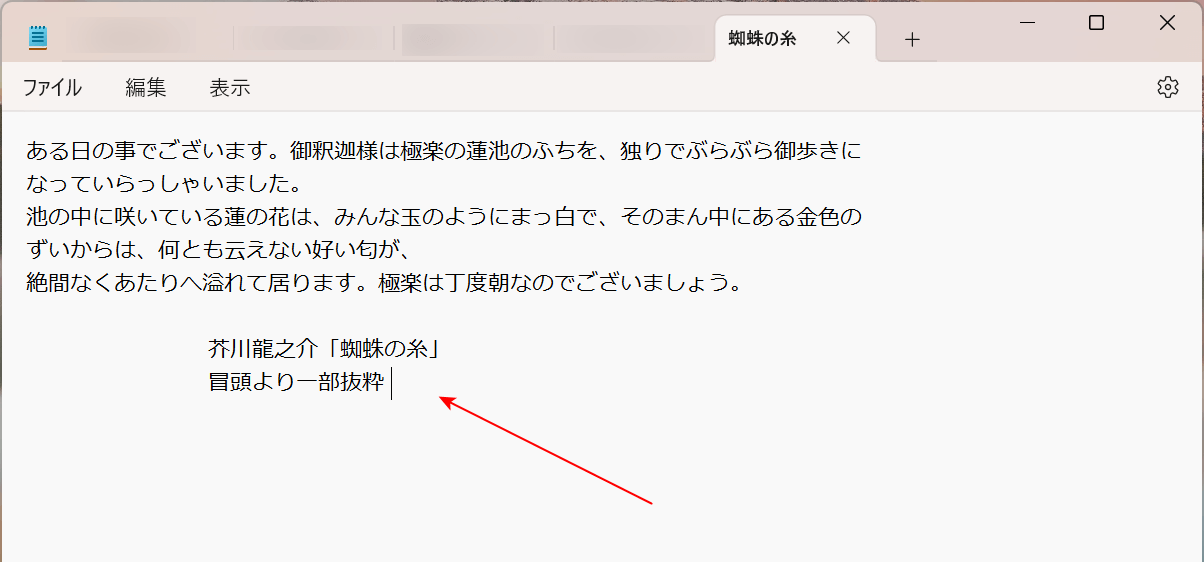
保存されたファイルを開いて確認します。
赤矢印で示す通り、Text形式で保存され、OCR処理をすることができました。
CamScannerの基本情報
CamScanner
- 無料のお試しを押したら12000円決済になってしまった。
日本語: ×
オンライン(インストール不要): 〇
オフライン(インストール型): 〇
CamScannerでPDFのOCR処理を行う方法
CamScannerでPDFのOCR処理を行う方法をご紹介します。
PDFスキャン/変換サービスで、デスクトップ版はWindows/Mac、アプリ版はiOS/Androidに対応しています。
ほとんどの機能を無料で使用できますが、インストール後はアカウント登録が必要です。
今回はWindows 11を使って、CamScannerのデスクトップ版でPDFのOCRを行う方法をご紹介します。
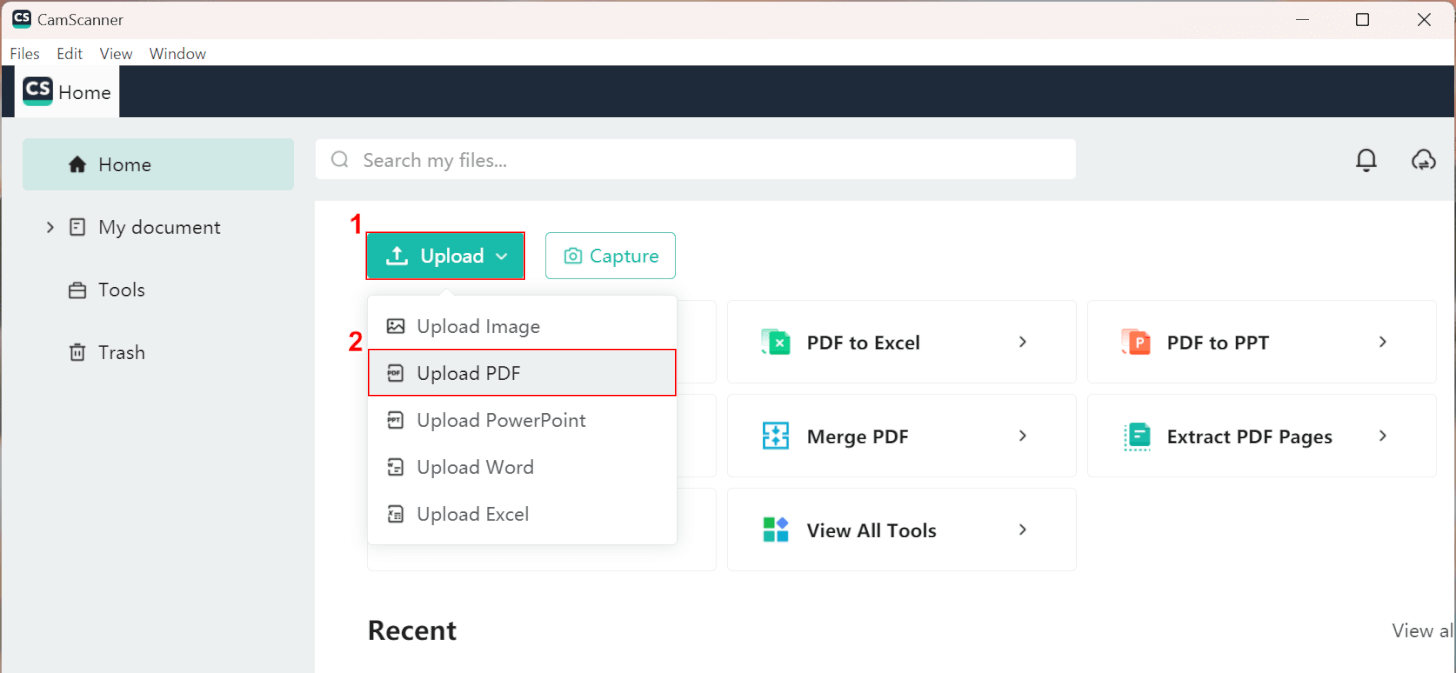
CamScannerを起動します。
①「Upload」、②「Upload PDF」の順に選択します。
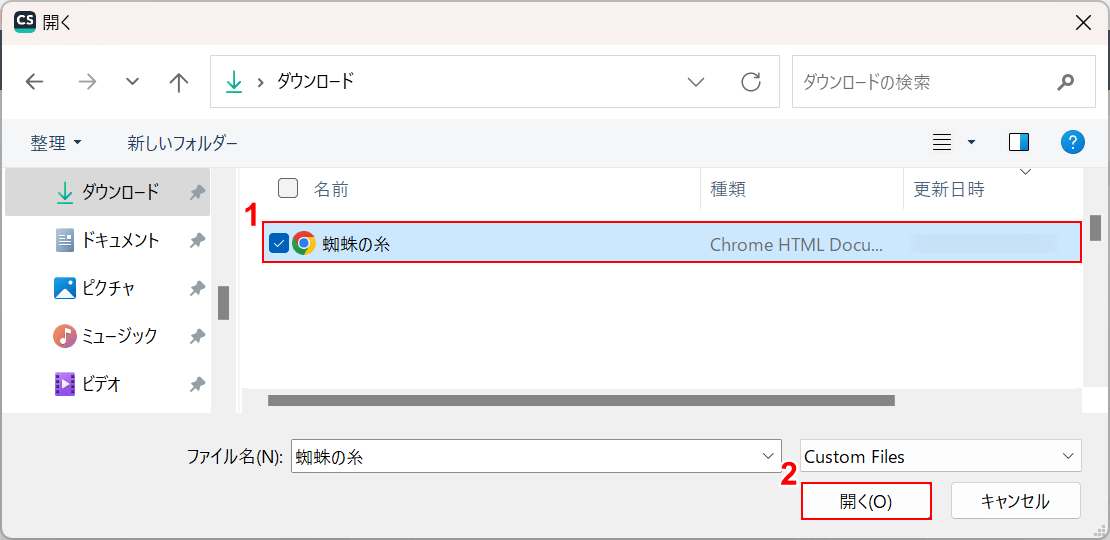
「開く」ダイアログボックスが表示されます。
①OCR処理したいPDFファイル(例:蜘蛛の糸)を選択し、②「開く」ボタンを押します。
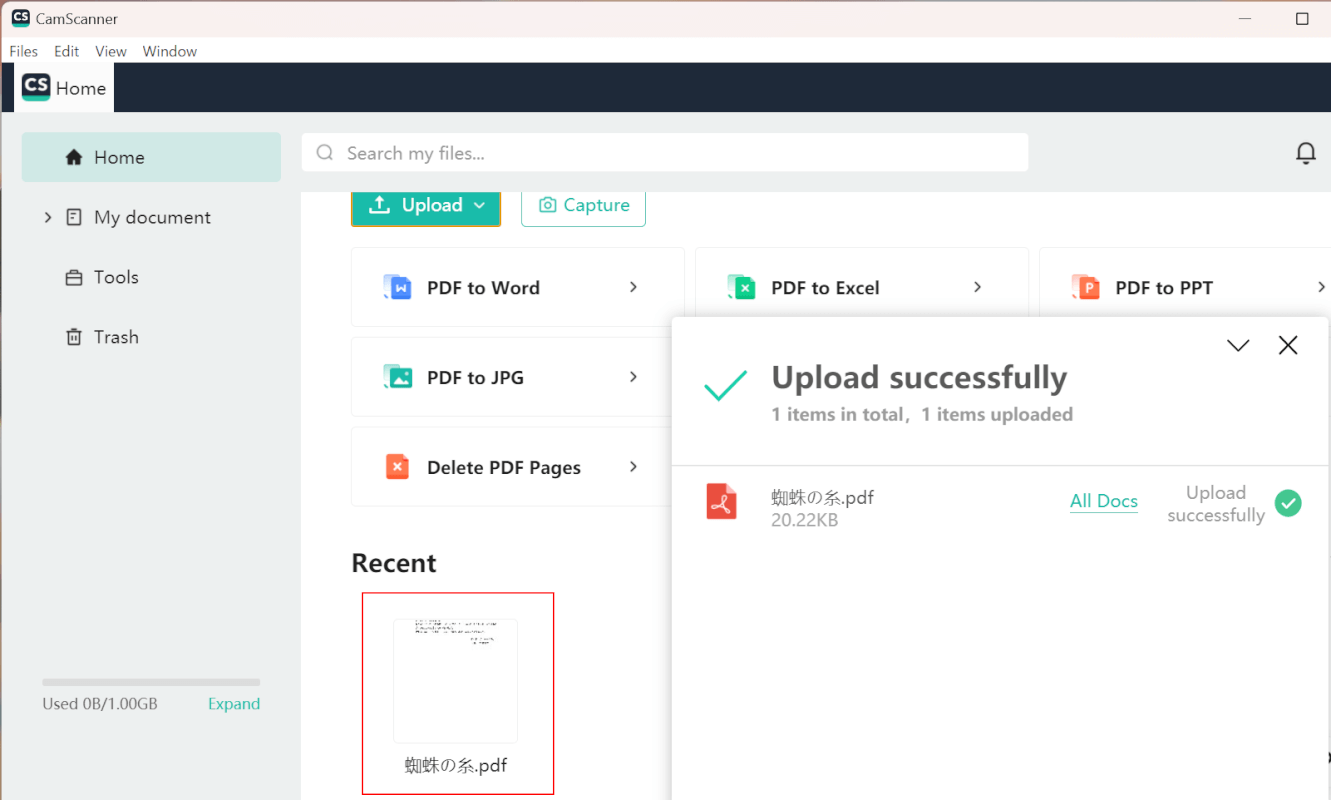
選択したファイルがアップロードされます。
「Recent」でアップロードしたファイルを選択します。
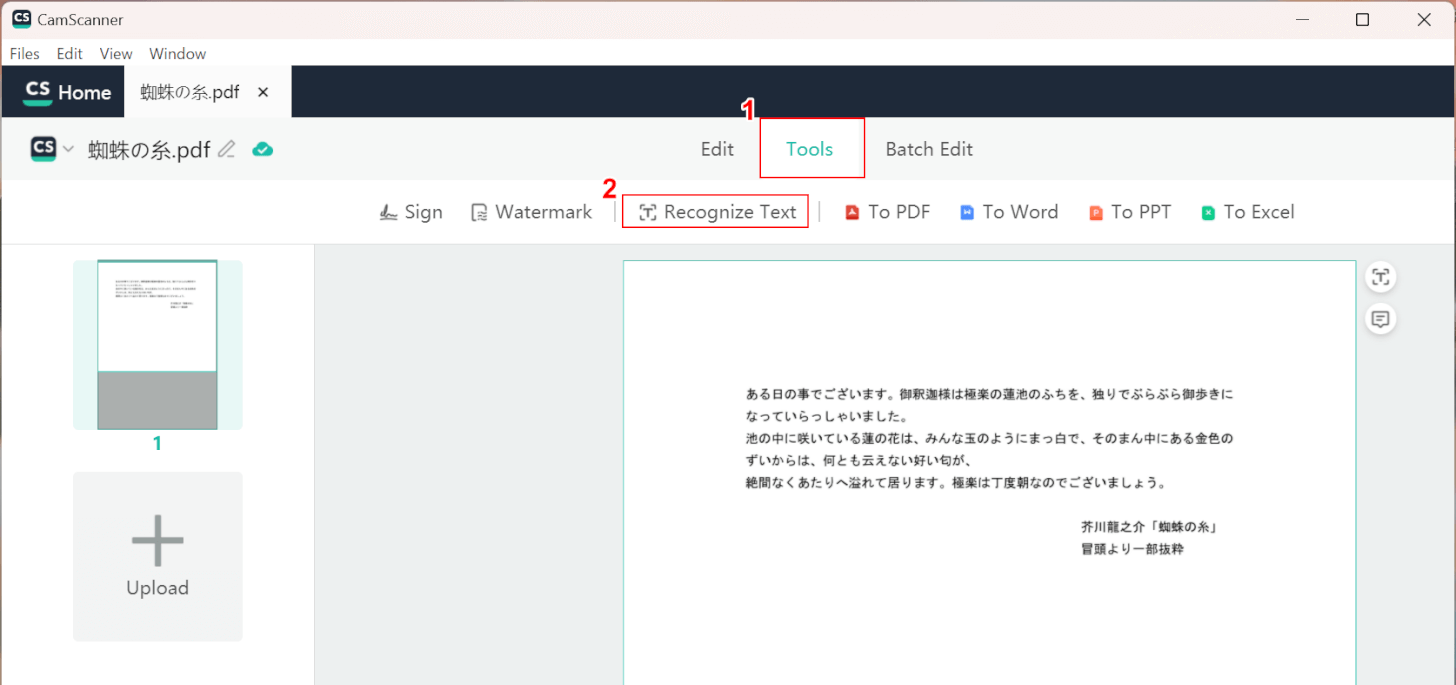
選択したファイルが表示されます。
①「Tools」タブ、②「Recognize Text」の順に選択します。
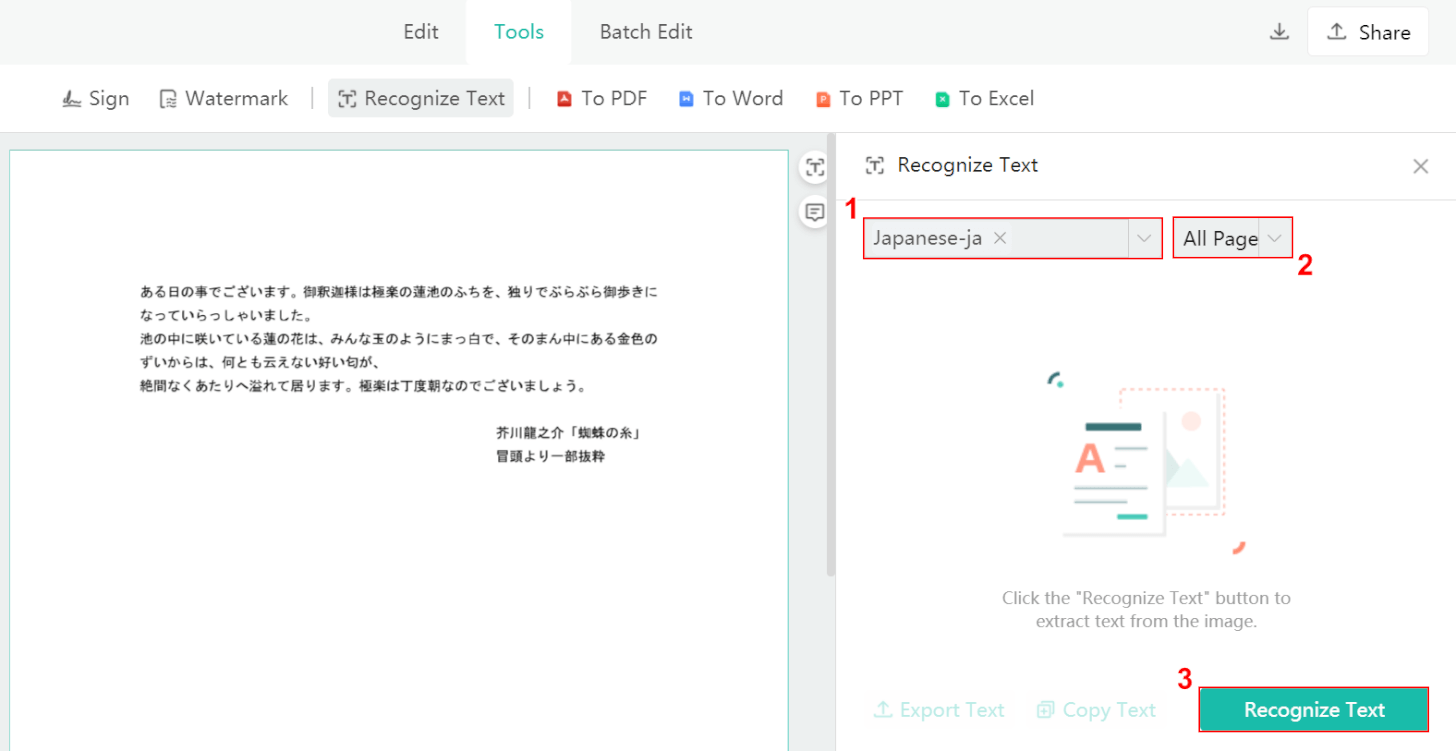
①ファイルのテキスト言語(例:Japanese-ja)、②任意の処理ページ(例:All Page)の順に選択します。
③「Recognize Text」ボタンを押します。
上記のポップアップが表示されるので、「Continue」ボタンを押します。
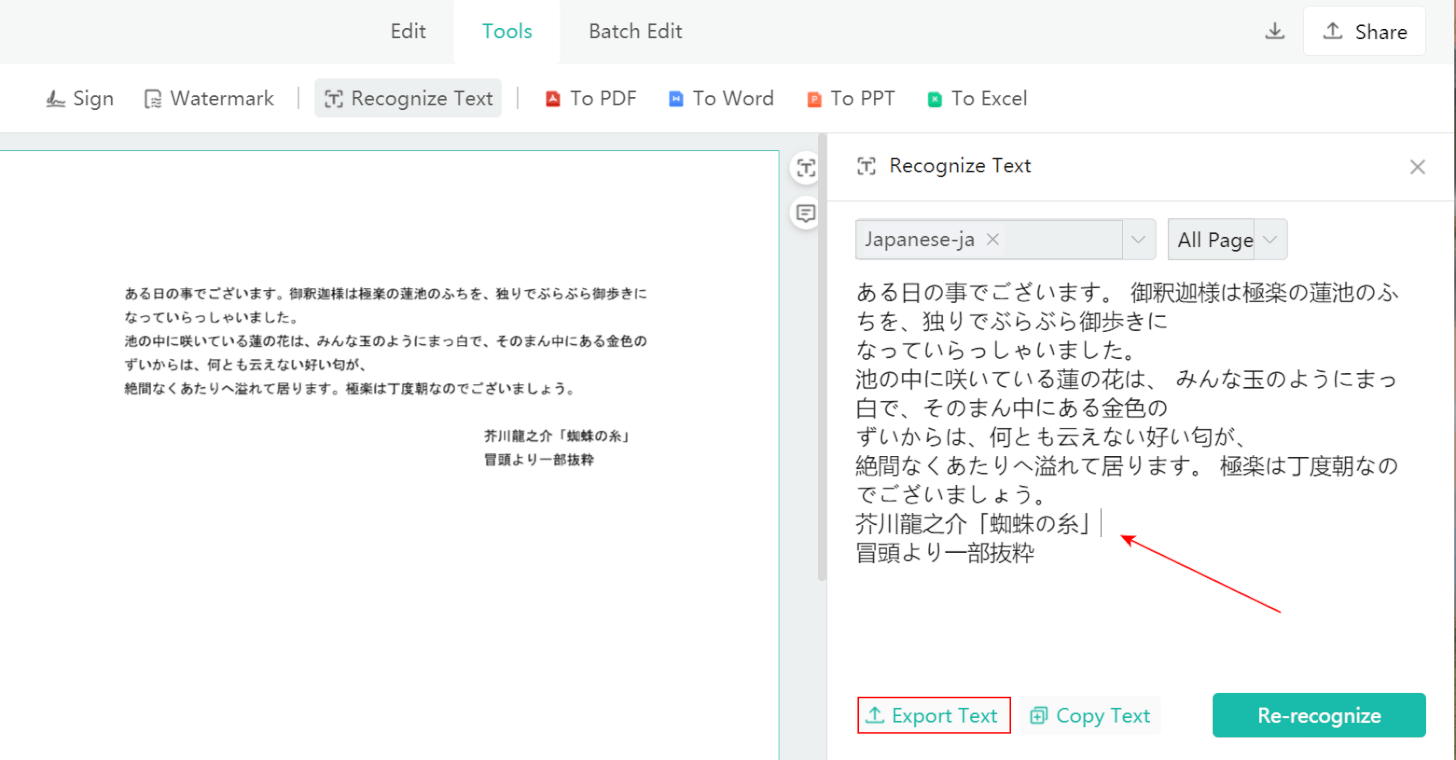
画面右側にテキスト化されたものが表示されます。
「Export Text」ボタンを押します。
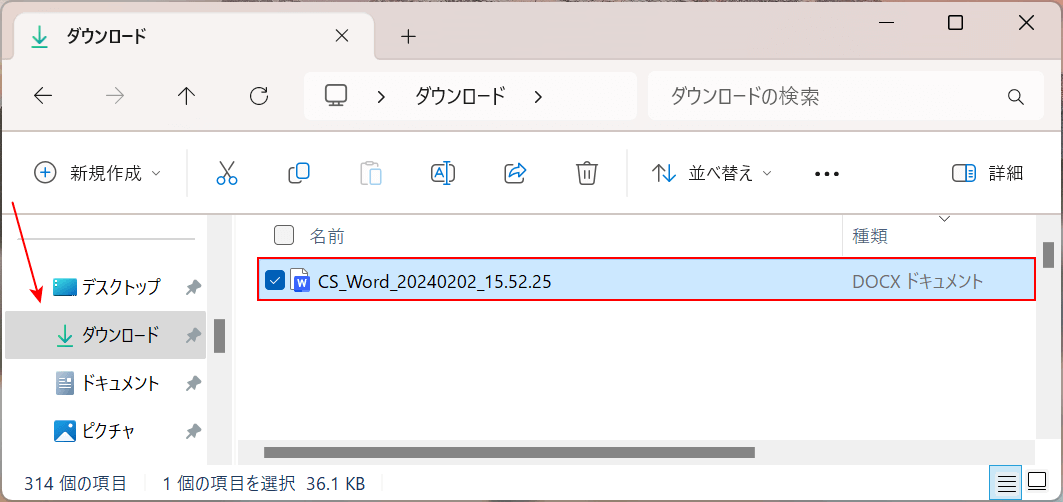
変換前のPDFが格納されていた場所(例:ダウンロード)に自動でWord形式のファイルとして保存されます。
保存されたファイル(例:CS_Word_20240202_15.52.25)を選択して開きます。
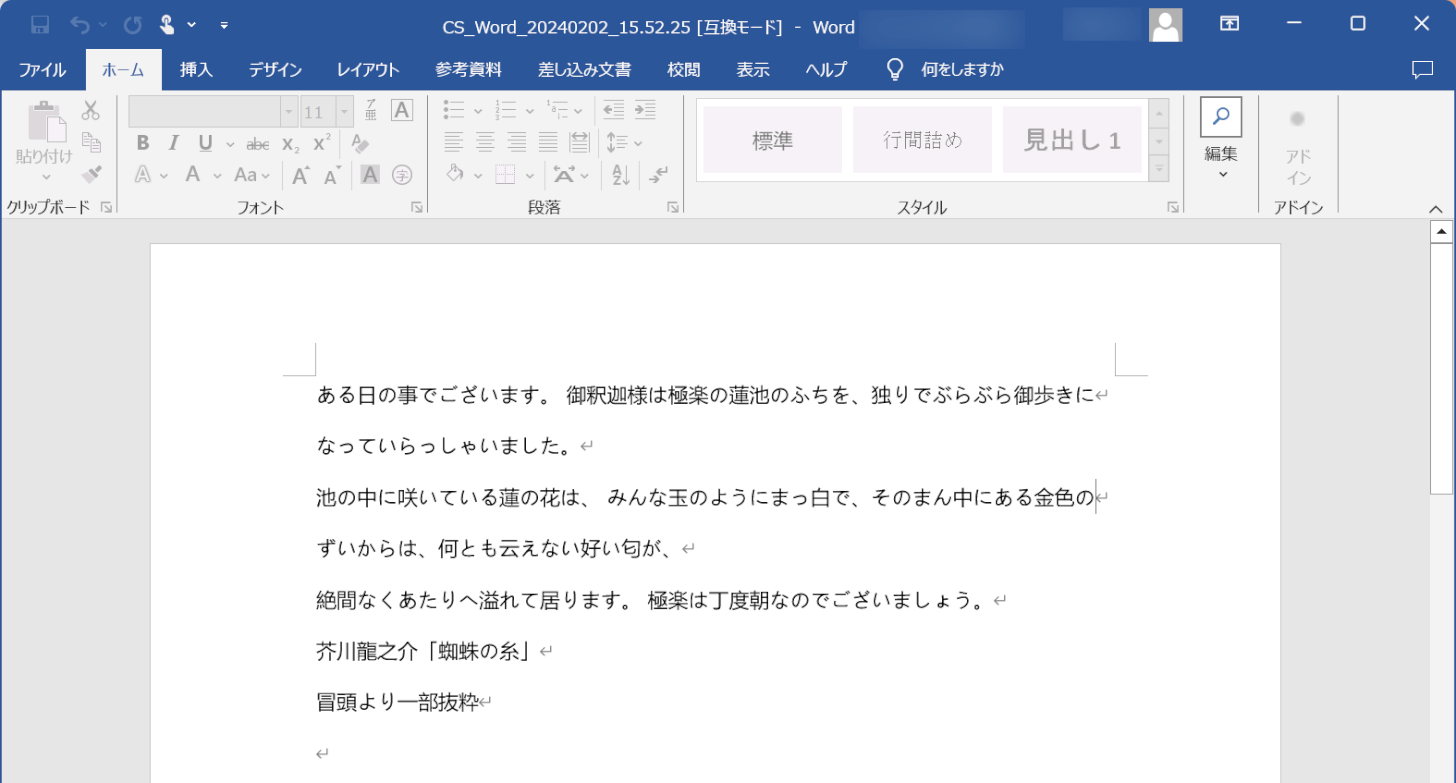
PDFをWord形式に変換し、OCR処理することができました。
問題は解決できましたか?
記事を読んでも問題が解決できなかった場合は、無料でAIに質問することができます。回答の精度は高めなので試してみましょう。
- 質問例1
- PDFを結合する方法を教えて
- 質問例2
- iLovePDFでできることを教えて
コメント
この記事へのコメントをお寄せ下さい。